the lynne teaches tech import begins... and so does my sleep, it's 3:30am
This commit is contained in:
parent
7d1199c5db
commit
31794b6e31
27 changed files with 1076 additions and 0 deletions
|
|
@ -0,0 +1,173 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: What do the various graphics settings in PC games mean?"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
This is going to be a fair bit longer than the average Lynne Teaches Tech post, due to the sheer amount of info that needs to be covered.
|
||||||
|
|
||||||
|
Most PC games include a smattering of graphical options to configure, ranging from the obvious, like brightness and resolution, to more confusing ones, such as chromatic aberration and ambient occlusion. This post will attempt to explain as many as possible, and may occasionally be updated to add more. Feel free to leave a comment if I missed one!
|
||||||
|
|
||||||
|
<!--more-->
|
||||||
|
This article is structured so that the easier to understand sections come first, with the more complicated stuff later on. There's also a table of contents provided so you can jump to a particular section if you're using this post as a reference, or if you just want to know about one thing in particular.
|
||||||
|
|
||||||
|
*While some people use the term PC to refer exclusively to Windows computers, in this post, it will mean any operating system aimed at traditional computers, such as Windows, macOS, and Linux.*
|
||||||
|
|
||||||
|
Display
|
||||||
|
-------
|
||||||
|
|
||||||
|
This section refers to settings that effect how the image is displayed on the screen.
|
||||||
|
|
||||||
|
### Resolution
|
||||||
|
|
||||||
|
Every display has a resolution. Your computer outputs video at some resolution, usually the same one as your display to ensure that everything looks as best as it can.
|
||||||
|
|
||||||
|
Higher resolutions mean that your display needs to create more information. It's a lot simpler to render 1,000 pixels than it is to render 10,000, because the graphics card doesn't need to create as much information. One common display resolution is 1920 pixels wide by 1080 pixels high, or 1920x1080 (also known as 1080p). At a resolution of 1920x1080, your graphics card needs to generate 2,073,600 pixels, or 2.07 megapixels, of information. Meanwhile, 1280x720, another common standard, is only 0.92 megapixels, and is therefore much easier for a computer to process. 4K, or 3840x2160\[efn\_note\]This is the "standard" 4K resolution, but there are others\[/efn\_note\], is a massive 8.29 megapixels.
|
||||||
|
|
||||||
|
 *on* [*Unsplash*](https://unsplash.com)](https://wasabi.lynnesbian.space/bune-city/2019/05/a4a48eae19d6ecf4f5a01eed7471182d/comparison.jpg){.wp-image-337}
|
||||||
|
|
||||||
|
Higher resolutions look better, but come at the cost of performance. If your computer's really struggling to play a game, you might want to consider turning this down, but be aware that things will look noticeably blurrier, and you'll get a lot less detail.
|
||||||
|
|
||||||
|
#### Internal Resolution
|
||||||
|
|
||||||
|
Some games offer a setting to change the internal resolution as well as the resolution. This might seem a little confusing, but it's actually quite simple.
|
||||||
|
|
||||||
|
Suppose you have a 1080p display, but you can't handle running a game at that resolution, so you turn it down to 720p. Everything becomes less detailed, including the in-game menus and overlays. Internal resolution fixes that: It allows you to set the game's graphics to run at a lower resolution, while the menus remain at full resolution. This means that you get crisp subtitles, buttons, health meters, and more, while still running the game at a lower resolution. If a game offers you the option to change the internal resolution, you'll want to do this instead of the standard resolution setting. It offers nearly zero performance penalty for a great benefit.
|
||||||
|
|
||||||
|
### Brightness, Contrast, Saturation, and Gamma
|
||||||
|
|
||||||
|
These three are pretty simple, so I won't spend too long on them.
|
||||||
|
|
||||||
|
Brightness is, as the name suggests, how bright the image is. Turning up the brightness makes everything brighter, from the shadows to the lights.
|
||||||
|
|
||||||
|
Contrast is the difference between black and white. A low contrast means the range of brightness is squished together, with less dark blacks and less bright whites. Having this too low makes everything look terrible, but having it too high makes it look like the brightness is exaggerated.
|
||||||
|
|
||||||
|
Saturation is how vibrant the colours are. High saturation makes colours "pop" more, but also makes things look less realistic.
|
||||||
|
|
||||||
|
Gamma is \[TODO\] https://gaming.stackexchange.com/a/80986
|
||||||
|
|
||||||
|
### Fullscreen, Windowed, and Borderless Windowed Mode
|
||||||
|
|
||||||
|
Fullscreen programs take direct control of your computer's display space. If a fullscreen game is running at a different resolution than your operating system, then it will tell it to change the resolution to match the game. This can occasionally cause problems with using alt-tab if the game isn't built to handle being in the background, and if the game changes the resolution, alt-tabbing will sometimes mean changing the resolution back to the previously set one.
|
||||||
|
|
||||||
|
Windowed mode means that the game runs in a window, just like pretty much every other program.
|
||||||
|
|
||||||
|
Borderless windowed mode is a special setting that is sort of a mix between the two. The game will run in a window without the usual window decorations (such as the title bar and close button), and will usually take up the entire screen. This means that you can easily alt-tab between programs and get notifications, while also taking up the entire screen and not wasting space with close buttons and such nonsense.
|
||||||
|
|
||||||
|
### VSync
|
||||||
|
|
||||||
|
Every display has a refresh rate. This is the number of times it can update the screen per second. Most monitors typically have a refresh rate of 60Hz, meaning they can update the screen 60 times per second. A 60Hz monitor is therefore perfectly suited for playing games at 60FPS, or 60 frames per second. It also works well for 30FPS content, as 60 is cleanly divisible by 30, and the monitor can just display each frame twice.
|
||||||
|
|
||||||
|
However, games don't usually run at a perfectly stable 60FPS all the time. When things get more graphically intense, your computer might not be able to run the game at the full 60FPS, and might drop to, say, 50. Your 60Hz monitor can't display 50FPS content nicely, because they aren't evenly divisible. The game might also run at a *higher* framerate than the monitor can handle if your PC can handle it, and 70FPS content won't look good on a 60Hz monitor either.
|
||||||
|
|
||||||
|
To make this more mathematically simple, let's imagine a 3Hz monitor playing 2FPS footage. The monitor is ready to display a new frame 3 times per second, but there's only a new frame to display 2 times per second. The monitor can't "wait" for the frame to be ready, it always runs at the same speed. So when the monitor tries to display the frame, the graphics card hasn't finished rendering it yet. This means that it only displays some of the frame. This leads to screen tearing.
|
||||||
|
|
||||||
|
The same thing happens if the game is running too fast. If a 3Hz monitor tries to display 4FPS footage, by the time it updates, the graphics card has already started rendering a new frame, and the monitor displays some of the new frame over the top of the previous one.
|
||||||
|
|
||||||
|
Let's say that the monitor and game are running at a rate where the first frame displays perfectly, but when the monitor tries to show the second frame, it's only half-finished. This would mean that the top half of the second frame appears on the monitor, but the bottom half of the first frame is still there. Since video games don't tend to have massive changes between each frame, rather than looking like two completely different images overlapping each other, it will tend to look like one image with a "tear" in the middle.
|
||||||
|
|
||||||
|
*\],* [*via Wikimedia Commons*](https://commons.wikimedia.org/wiki/File:Tearing_(simulated).jpg)](https://wasabi.lynnesbian.space/bune-city/2019/05/ca88ba8a6abbeb74a968288e0b1ae8c8/Tearing_simulated-1024x770.jpg){.wp-image-343}
|
||||||
|
|
||||||
|
Of course, if there *has* been a huge change between frames (a cutscene with a jumpcut, pausing the game...), it will look even more out of place.
|
||||||
|
|
||||||
|
If your monitor runs at 60Hz, each tear will only be visible for 1/60th of a second. However, since the output will most likely tear every single frame, there will be a new tear somewhere else every time the monitor refreshes. This can be very distracting. VSync can deal with visual tearing in multiple ways:
|
||||||
|
|
||||||
|
#### Double Buffering
|
||||||
|
|
||||||
|
The graphics card will keep the old frame in memory, and whenever the monitor asks for an update, it will send the old frame. Meanwhile, it will render the new frame. When the graphics card is finished with the new frame, it will wait for the monitor to ask for an update, and send the new frame. It will then store the new frame as the old frame, and start working on the next new frame. As a side effect, this means that the game will be limited to a framerate cleanly divisible by your monitor's refresh rate. For example, if you have a 60FPS monitor, the game will only be able to display at 60FPS, 30FPS, 15FPS, and so on - numbers cleanly divisible by 60.
|
||||||
|
|
||||||
|
#### Triple Buffering
|
||||||
|
|
||||||
|
Triple buffering works similarly to double buffering, but works in a way independent of the monitor's refresh rate. It never needs to wait for the monitor to refresh, meaning that the game isn't limited to a divisor of 60Hz (or whatever your monitor's refresh rate is). The way this is achieved is a little more technical.
|
||||||
|
|
||||||
|
As the name suggests, triple buffering makes use of three buffers, areas of memory where the computer is able to store completed frames\[efn\_note\]A buffer is an area in memory where things are temporarily stored while other stuff is going on in the background. It isn't exclusive to VSync.\[/efn\_note\]. Triple buffering uses one "front" buffer and two "back" buffers to store the video. Whenever the display needs an update, it asks the front buffer for it. Meanwhile, the graphics card can render the new frame to one of the back buffers, where it can then be copied into the front buffer. You can read about this in more detail [here](https://en.wikipedia.org/wiki/Multiple_buffering#Triple_buffering).
|
||||||
|
|
||||||
|
#### Adaptive VSync
|
||||||
|
|
||||||
|
Adaptive VSync enables VSync when the framerate exceeds your monitor's refresh rate, and disables it otherwise. This is a "best of both worlds" approach that means you don't get tearing when the game is running too fast, but you don't get locked to a divisor of your monitor's refresh rate when it's running too slow. This means that you'll still experience tearing when the game is running at a lower framerate than your monitor's refresh rate, but most people would rather have tearing at 50FPS than a game running at only 30FPS.
|
||||||
|
|
||||||
|
Adaptive VSync is a feature implemented by both AMD and Nvidia GPUs. Nvidia has an article about it [here](https://www.geforce.com/hardware/technology/adaptive-vsync/technology).
|
||||||
|
|
||||||
|
#### FreeSync/GSync
|
||||||
|
|
||||||
|
These methods provide the best possible solution to the problem by approaching it from the other side: Instead of changing the GPU's framerate, they change the monitor's refresh rate to adapt to the video signal, eliminating tearing without requiring framerate changes or memory buffers. This requires that you have a GPU *and* a monitor that are compatible with the technology.
|
||||||
|
|
||||||
|
Effects
|
||||||
|
-------
|
||||||
|
|
||||||
|
We'll now turn our attention to settings that provide different visual effects.
|
||||||
|
|
||||||
|
### Bloom
|
||||||
|
|
||||||
|
Bloom is one of many visual effects in modern video games designed to emulate the behaviour of a camera. While this doesn't make much sense in most first person games (if you're looking through the eyes of a living creature, why do your "eyes" behave like cameras?), it is commonly seen in a lot of video games.
|
||||||
|
|
||||||
|
Bloom replicates the way that cameras show light "bleeding" from bright objects to their darker surroundings.
|
||||||
|
|
||||||
|
*\],* [*via Wikimedia Commons*](https://commons.wikimedia.org/wiki/File:HDRI-Example.jpg)](https://wasabi.lynnesbian.space/bune-city/2019/05/b8532efc51206d8495cba65aca303372/bloom.jpg){.wp-image-346 width="384" height="239"}
|
||||||
|
|
||||||
|
Bloom typically incurs little to no performance impact, as it requires very little processing power.
|
||||||
|
|
||||||
|
Nvidia has a comparison page where you can see the difference between bloom being enabled and disabled on a screenshot of the game *Tom Clancy's Rainbow Six Siege* [here](https://images.nvidia.com/geforce-com/international/comparisons/tom-clancys-rainbow-six-siege/tom-clancys-rainbow-six-siege-lens-effects-interactive-comparison-001-bloom-vs-off.html).
|
||||||
|
|
||||||
|
### Lens Flare
|
||||||
|
|
||||||
|
](https://wasabi.lynnesbian.space/bune-city/2019/05/967d9583d1a0e40409814bcbd4faf41f/lens-flare-1024x576.jpg){.wp-image-347}
|
||||||
|
|
||||||
|
Lens flare is another effect that aims to simulate the behaviour of cameras. It has very little performance penalty, although some may find it obnoxious or unrealistic.
|
||||||
|
|
||||||
|
### Chromatic Aberration
|
||||||
|
|
||||||
|
Chromatic aberration occurs when a camera lens fails to line up the red, green, and blue channels that make up an image.
|
||||||
|
|
||||||
|
*\],* [*via Wikimedia Commons*](https://commons.wikimedia.org/wiki/File:Nearsighted_color_fringing_-9.5_diopter_-_Canon_PowerShot_A640_thru_glasses_-_closeup_detail.jpg)](https://wasabi.lynnesbian.space/bune-city/2019/05/7d0a8f8e80c500f4b16c58ace0358455/CA-1024x819.jpg){.wp-image-349}
|
||||||
|
|
||||||
|
Again, not much performance impact with this one. Whether or not you enable it is a matter of taste.
|
||||||
|
|
||||||
|
### Motion Blur
|
||||||
|
|
||||||
|
This one applies to eyes, too! When you move something very quickly, you'll notice it looks kinda blurry. Motion blur attempts to recreate this by adding a blur whenever you move the in-game camera quickly. This is another "matter of taste" option.
|
||||||
|
|
||||||
|
Performance
|
||||||
|
-----------
|
||||||
|
|
||||||
|
This section covers settings that are there for performance reasons.
|
||||||
|
|
||||||
|
### Models (or Model Quality)
|
||||||
|
|
||||||
|
3D objects in computer graphics are made up of polygons, typically triangles (also called "tris", pronounced tries) or rectangles ("quads"). You can create any 3D object out of these polygons. A ball made up of only 50 polygons wouldn't look very good, but a 500 polygon ball would look a lot better. However, this comes at a performance cost. Models with more polygons look better and less "computery", but require more graphics processing power.
|
||||||
|
|
||||||
|
![A simple model of a car made up of quads.
|
||||||
|
*Pauljs75 at English Wikibooks \[Public domain\],* [*via Wikimedia Commons*](https://commons.wikimedia.org/wiki/File:W3D_all_quad_car_Step33.jpg)](https://upload.wikimedia.org/wikipedia/commons/5/51/W3D_all_quad_car_Step33.jpg)
|
||||||
|
|
||||||
|
A computer has to render more than just the polygons themselves. It also needs to apply lighting, shading, and textures to them, which makes high-poly model processing very intense.
|
||||||
|
|
||||||
|
### Textures
|
||||||
|
|
||||||
|
Textures are the images that are applied to the models. For example, you might have a model of a tree, and then an image that is applied to the model to make it look like a tree. Without a texture, a model looks like the car above: A single uniform colour, possibly with lighting and shading applied\[efn\_note\]It's also possible to set the colours of polygons individually, either with an algorithm or a preset list of colours, but we won't go into that here.\[/efn\_note\].
|
||||||
|
|
||||||
|
Higher resolutions textures look better, but require more VRAM (video memory) and processing power.
|
||||||
|
|
||||||
|
![A demonstration of how a texture image is mapped onto a 3D model.
|
||||||
|
*Drummyfish \[CC0\],* [*via Wikimedia Commons*](https://commons.wikimedia.org/wiki/File:Texture_mapping_demonstration_animation.gif)](https://wasabi.lynnesbian.space/bune-city/2019/05/02469efe16c9d6d48da0ff91e4a3580c/Texture_mapping_demonstration_animation.gif){.wp-image-350}
|
||||||
|
|
||||||
|
### Bilinear, Trilinear, and Anisotropic Filtering
|
||||||
|
|
||||||
|
These are all methods of rendering textures that aren't angled parallel to the camera. A common example is the ground stretching off into the distance. Bilinear and trilinear filtering are much less resource intensive than anisotropic filtering.
|
||||||
|
|
||||||
|
\], [via Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Anisotropic_filtering_en.png)](https://wasabi.lynnesbian.space/bune-city/2019/05/b06fb8f6d7b233f44d9aeb31b596e641/anisotropic-1024x484.jpg){.wp-image-351}
|
||||||
|
|
||||||
|
### Level of Detail
|
||||||
|
|
||||||
|
To save processing power, games will often replace distant textures and models with lower quality ones. If done well enough, this can be almost imperceptible. Games typically give you a slider to choose how aggressive you want the effect to be, with the minimum setting only effecting extremely distant objects (or sometimes disabling LOD altogether), and the highest setting meaning that models and textures are replaced with lower quality versions very quickly.
|
||||||
|
|
||||||
|
Summary
|
||||||
|
-------
|
||||||
|
|
||||||
|
This article isn't finished yet! Thanks for reading what I've written so far, though! :mlem:
|
||||||
|
|
||||||
|
|
@ -0,0 +1,15 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: How do mstdn-ebooks bots work?"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech, Originally from the Fediverse]
|
||||||
|
tags: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
the ebooks bots (the ones i using [the code i made](https://github.com/Lynnesbian/mstdn-ebooks), anyway) use something called [markov chains](https://en.wikipedia.org/wiki/Markov_chain). markov chains are a mathematical concept, and in computer science (computers are the only thing i know about), they are generally used for predictive text. when you type "how are" on your phone and the keyboard recommends "you", that's (usually) markov chains at work! as you type, your keyboard makes a database of everything you've ever typed and uses it to predict what you'll type next. keyboard generally come with a built-in database of common phrases, and then additionally learn from you as you type. this is why your brand new phone already knows to suggest "you" after "how are", before you've ever even said that before.
|
||||||
|
|
||||||
|
mstdn-ebooks use markov chains too! every time they're asked to post, they use a random selection of 10,000 posts (they use less if you haven't made that many) to learn from and use them to generate a new one. that means when you reply, they receive your reply, randomly select a huge chunk of posts, train a markov chain on them, generate a reply, and post it -- all in less than a second! technology!!
|
||||||
|
|
||||||
|
a markov chain isn't intelligent. it doesn't know where sentences start and end, and it doesn't understand grammar -- it doesn't know anything apart from "when you say this word, you usually say this one next". markov chains don't care if the input is words or colours or images or DNA sequences, they just have a database of items and probabilities and use them to create posts. they often make things that don't make sense, or just feel like two posts slammed together, but occasionally, they come up with gold (such as "[have these ancap nerds even played Super Mario 64](https://fedi.lynnesbian.space/web/statuses/100987016408210808)").
|
||||||
|
|
||||||
|
[view original post](https://fedi.lynnesbian.space/web/statuses/101548793919202772)
|
||||||
|
|
||||||
|
|
@ -0,0 +1,17 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: How does OCRbot work?"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech, Originally from the Fediverse]
|
||||||
|
tags: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
after downloading the image, [OCRbot](https://github.com/Lynnesbian/OCRbot) uses [tesseract-ocr](https://github.com/tesseract-ocr/tesseract) to extract the text. this is a free (as in libre and gratis) program that uses neural networks to do the job. it's been trained on a massive dataset of text and has "learned" what letters usually look like. it knows that a lowercase h is a line with a smaller line connected to it on the right, for example.
|
||||||
|
|
||||||
|
tesseract first tries to split the image into chunks of what it believes to be text. it then splits these chunks into words by looking for spaces, and then tries to identify the letters making up those words. if any of these steps fail, the entire process fails.
|
||||||
|
|
||||||
|
neural networks work in a similar way to how a brain does, but on a much smaller scale - computers really aren't up to the task of simulating an entire brain right now. powerful computers are used to train the neural network for hours and hours, making it become more accurate at reading text. this has some drawbacks - if it was always trained on helvetica text, it'd only be able to read that, for example. thus it's important to make sure you train it on lots of different fonts. tesseract provides these datasets for you, but you can train your own if you'd like.
|
||||||
|
|
||||||
|
finally, after extracting the text, OCRbot does some rudimentary fixes (like replacing \| with I, as tesseract thinks \| is a lot more frequent than it really is) and posts the reply.
|
||||||
|
|
||||||
|
[view original post](https://fedi.lynnesbian.space/web/statuses/101758028785197240)
|
||||||
|
|
||||||
|
|
@ -0,0 +1,18 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: The DK64 Memory Leak"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech, Originally from the Fediverse]
|
||||||
|
tags: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
Donkey Kong 64 was about to be released when the developers discovered that there was a memory leak that caused the game to crash after a few minutes. There was no time to fix it, so what they did instead was require the game to be played with the expansion pak, which doubled the N64's RAM. This meant that the game would only crash after \~10 hours rather than a few minutes.
|
||||||
|
|
||||||
|
Computers have two main types of storage: the hard drive (or solid state drive), which is where you keep your documents, videos, etc., and memory (or RAM), which is where the computer stores things it's currently "thinking about". If you have a document open in powerpoint, it's in memory. Memory is a LOT faster than the hard drive, so it's preferable to use it when possible.
|
||||||
|
|
||||||
|
A memory leak is when you keep putting things in memory without taking them out, causing the amount of memory used to slowly go up and up until the computer runs out of memory and crashes. This is what happened with DK64.
|
||||||
|
|
||||||
|
The expansion pak added more memory to the Nintendo 64 (the system DK64 runs on), which meant that running out of memory would take a lot longer (in this case, ten hours instead of a few minutes). It's not a fix, but it was good enough.
|
||||||
|
|
||||||
|
[View original post
|
||||||
|
](https://fedi.lynnesbian.space/web/statuses/101514903220023730)
|
||||||
|
|
||||||
|
|
@ -0,0 +1,29 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: What do all the parts of a URL or hyperlink mean?"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech, Originally from the Fediverse]
|
||||||
|
tags: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
when you access a website in your browser, its URL (Universal Resource Location) will almost always start with either https:// or http://. this is known as the schema, and tells the browser what type of connection it's going to be using, and how it needs to talk to the server. these aren't the only schemas - another common one is ftp, which is natively supported by most browsers. try opening this link: <ftp://ftp.iinet.net.au/pub/>
|
||||||
|
|
||||||
|
a hyperlink (or just link) is a name for a clickable or otherwise interactive way to access a URL, typically represented by blue underlined text. clicking a link opens a URL and not the other way around.
|
||||||
|
|
||||||
|
the next part of a URL is the domain name, which may be preceded by one or more subdomains. for example:
|
||||||
|
google.com - no subdomain
|
||||||
|
docs.google.com - subdomain "docs"
|
||||||
|
|
||||||
|
a common subdomain is "www", for example, www.google.com. using www isn't necessary and contains no special meaning, but many websites use or used it to indicate that the subdomain was intended to be accessed by a web browser. for example, typical webpages could be at www.example.com, with FTP files stored at ftp.example.com.
|
||||||
|
|
||||||
|
the ".com" at the end of a URL is a TLD, or Top Level Domain. these carry no special meaning to the computer, but are used to indicate to the user what type of website they're accessing. government websites use .gov, while university sites use .edu. you can have multiple TLDs - for example, <https://australia.gov.au>
|
||||||
|
|
||||||
|
in "example.com/one/two", "/one/two" is the path. this is the path to the file or page you want to access, similarly to how the path to your user folder on your computer might be "C:\\Users\\Person".
|
||||||
|
|
||||||
|
some URLs end with a question mark and some other things, like "example.com?page=welcome". this is the query portion of the URL, which can be used to give the server some instructions. what this means varies from site to site.
|
||||||
|
|
||||||
|
finally, some URLs might end with a hash followed by a word, like example.com\#content. this is called a fragment or anchor, and tells the browser to scroll to a certain part on the page.
|
||||||
|
|
||||||
|
technically, a URL is only a URL if it includes the schema. this means that <https://example.com> is a URL, but example.com isn't - it's a URI, the I standing for Identifier. however, people will understand what you mean if you use them interchangeably.
|
||||||
|
|
||||||
|
[view original post](https://fedi.lynnesbian.space/@lynnesbian/101898501800196300)
|
||||||
|
|
||||||
|
|
@ -0,0 +1,14 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: What does \"decentralised\" mean?"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech, Originally from the Fediverse]
|
||||||
|
tags: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
Let's use twitter and mastodon for our examples.
|
||||||
|
Twitter is centralised, while Mastodon is not. This means that it's possible for Twitter to disappear at any time - the CEO could (theoretically) shut it down and delete anything at a moment's notice. The company behind twitter has complete control over everything that shows up on Twitter, and can do whatever they please with it.
|
||||||
|
|
||||||
|
Even if Mastodon's creator decided to shut down mastodon.social, all of the other instances would work fine. Mastodon can't be blocked by the government or your school (individual instances can, but there's always more). Mastodon can't be shut down. Mastodon can't disappear. This is true of all decentralised software, from matrix.org to Pleroma to email. It's a lot harder for Mastodon or email to disappear than it is for Twitter or Tumblr to do the same.
|
||||||
|
|
||||||
|
[View original post](https://fedi.lynnesbian.space/web/statuses/101674915458010485)
|
||||||
|
|
||||||
|
|
@ -0,0 +1,17 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: What does HTTPS mean?"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech, Originally from the Fediverse]
|
||||||
|
tags: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
when you see a website that's HTTPS rather than HTTP, it means the connection is secure. most popular browsers will display a green padlock in the URL bar to symbolise that (and colour it yellow or red if something's wrong).
|
||||||
|
|
||||||
|
to verify that a connection is secure (and not just someone saying it's secure), you need a certificate, a file that verifies that you are who you say you are.
|
||||||
|
|
||||||
|
a certificate can be revoked at any time by anyone. you can deny facebook's certificate if you like, and facebook will stop loading for you. more importantly (and practically), the issuer of the certificate can deny it, and the site will stop working until they get a new one. this means that if facebook "goes rogue", the CA (certificate authority) is allowed to remove their certificate, guaranteeing (in theory) that if the site is HTTPS, it's definitely secure.
|
||||||
|
|
||||||
|
these certificates don't last forever. they need to be renewed, to prove that you're still there and still complying with them. as an example, gargron, the admin of mastodon.social, had certificate auto-renewal set up, which means the certificate will automatically get renewed when it's close to expiring. so why did the cert expire? why did mastodon.social go down? the answer is because while a new certificate was installed, it wasn't actually loaded. nginx, the server software that .social uses, was supposed to automatically load the new cert, but it didn't for some reason (computers are weird!), and thus .social went offline for about an hour.
|
||||||
|
|
||||||
|
[view original post](https://fedi.lynnesbian.space/web/statuses/101542386081739342)
|
||||||
|
|
||||||
|
|
@ -0,0 +1,28 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: What is \"free software\"? Why do people say software isn't free, even though you can download it for free from the app store?"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech, Originally from the Fediverse]
|
||||||
|
tags: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
There are a lot of ways you could define "free software". For example, you could say Candy Crush or CCleaner is free software, because you can install it for free.
|
||||||
|
|
||||||
|
When people say that software is "free as in freedom", or "libre", they mean something else. Under these definitions, neither Candy Crush nor CCleaner would be free software. In order to be free by these definitions, software generally needs to fulfil these four criteria:
|
||||||
|
|
||||||
|
- The ability to run the software for any reason, without restrictions. This means that the free version of TeamViewer is not libre, as it tells you that you must purchase a license to use it commercially.
|
||||||
|
- Being able to study and modify the program's inner workings. This requires the source code being available - just as you can't make your own version of a store-bought cake without the recipe (or some clever reverse engineering), it's necessary to have the source code readily available to easily modify a program. Software that doesn't provide the source code thus cannot fulfil this term, and software like Snapchat, which bans users for running modified versions, is definitely not one of these.
|
||||||
|
- Being allowed to redistribute the software. If you buy a MacBooks, you can install updates for free, but you certainly aren't allowed to redistribute these updates.
|
||||||
|
- Being allowed to distribute modified versions to others. If you're not allowed to download the app, make some changes, and send that to people, it breaks this rule. The YouTube app is free, but Google doesn't allow users to make their own changes to it and distribute it to others.
|
||||||
|
|
||||||
|
All of the software mentioned in those four basic rules is "free", but not free. All of the software mentioned goes against every one of the four freedoms. The distinction between "freely available" and "free to do as you please with" is often signified by saying "gratis" or "libre" - gratis software is free as in "free donuts", but libre software is free as in "freedom".
|
||||||
|
|
||||||
|
As with anything, it's hard to make clear cut rules to define what is and isn't an example of libre software. The [Cooperative Software License](https://lynnesbian.space/csl) (CSL) prohibits most companies from using the software, but is otherwise entirely libre. This violates the first rule above, because certain people aren't allowed to use the software, but I would say it's still a free software license (just a less permissive one), although many - including the Free Software Foundation - would disagree with me on that.
|
||||||
|
|
||||||
|
While the Free Software Foundation argues that the CSL is not free because of its restrictions on who can use it, they also argue that obfuscated JavaScript is not free because even though the source code is available, it has been intentionally made much harder to read and modify. Going back to our cake example for earlier, this is like if your storebought cake came with a recipe, but it was written in hard to read cursive handwriting and all the ingredients had been replaced with generic names, like "ingredient 6" and "ingredient 4". It's still technically a recipe, and if you can figure out what ingredients are being referred to, it'll still work, but the FSF would argue that that doesn't count. For a computer, obfuscated source code and non-obfuscated source code are the same thing - a computer doesn't care whether you call a button a pickle, it'll still understand that if the user clicks on the pickle, something needs to happen. But for a human, obfuscated code is much harder to read than plain code, and thus the FSF considers it different.
|
||||||
|
|
||||||
|
And finally, you might be interested in the Free Software Foundation's [article](https://www.gnu.org/philosophy/free-sw.en.html) on what is and isn't free software. This is where those four rules came from - the FSF calls them the four essential freedoms. It's worth noting that they again outline here that "Obfuscated 'source code' is not real source code and does not count as source code."
|
||||||
|
|
||||||
|
Neither of these links are necessarily an endorsement of the content contained within. Although the CSL page *is* hosted on my own server, which is an endorsement anyway.
|
||||||
|
|
||||||
|
[View original post](https://fedi.lynnesbian.space/@lynnesbian/101758159647256687)
|
||||||
|
|
||||||
|
|
@ -0,0 +1,17 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: what is the \"analogue loophole\"?"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech, Originally from the Fediverse]
|
||||||
|
tags: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
the "analogue loophole" (or the analog loophole) refers to the idea that no matter how hard you try to make sure nobody can make illegal copies of videos, music, or text, there's always a "hole" in the protection that occurs when it's no longer digital. digital content can be protected - video files can be encrypted, music players can limit you to five devices - but analogue signals can't be. for example, itunes can disallow you from putting a song on more than five computers, but if you play the song through your speakers and record it, what you do with it is beyond apple's control.
|
||||||
|
|
||||||
|
one of the few remaining analogue outputs on a modern device is the audio jack. this is where you connect your headphones or speakers. your laptop only knows that something's plugged in. it doesn't know what's connected. you could be playing it through earphones or a massive speaker system and it wouldn't be able to tell. meanwhile, HDMI is a digital output format. it can tell if it's been plugged into a TV or a recording device, and can automatically disable output if you're recording it to make it harder for you to make copies of movies.
|
||||||
|
|
||||||
|
if the audio jack is replaced by USB-C or bluetooth, it becomes possible to tell what you're connecting to the laptop or phone. your phone might disable audio playback on anything but headphones to prevent you from hosting a public event with the music. it could also detect a recording device that you're using to (for example) make a copy of a song you're listening to on spotify and turn off the playback.
|
||||||
|
|
||||||
|
of course, at some point, digital needs to become analogue. humans can't watch electrical pulses, we need to see patterns of light. we can't listen to streams of 1s and 0s, we need vibrations in the air. this means that it's impossible to truly defeat the analogue hole - no matter what you do, someone can always just point a camera at their TV. it'll have worse quality, but it can never be stopped.
|
||||||
|
|
||||||
|
[view original post](https://fedi.lynnesbian.space/web/statuses/101758262714214719)
|
||||||
|
|
||||||
|
|
@ -0,0 +1,39 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: What's an integer overflow?"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech, Originally from the Fediverse]
|
||||||
|
tags: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
most people count using a decimal system. the lowest digit is 0, followed by 1, 2, and so on, through to 9. when you're counting up and you reach nine, you need to add another digit. there's no way to express ten with only one digit, so you use two digits to write 10.
|
||||||
|
|
||||||
|
computers use a binary number system instead. the lowest digit is 0, followed by 1, and that's it! so when you count to one, you need to add another digit to get to two, which is written as 10 in binary.
|
||||||
|
|
||||||
|
in decimal, from left to right, the digits mean ones, tens, hundreds, thousands, ten thousands... this means that a 4 in the third position (followed by two zeroes) means four hundred. from left to right, binary digits mean ones, twos, fours, eights... a 1 in the fourth position means eight, which is written as 1000. decimal uses powers of 10, binary uses powers of 2.
|
||||||
|
|
||||||
|
let's say you can only write two digits on a piece of paper. you can easily write numbers like 12 and 8 and 74, but what about 100? there's nothing you can do. but let's assume you aren't aware of that, and you're a computer following a simple algorithm calculating 99+1. first, you increment the least significant digits, which is the leftmost one. this leaves you with 90, and you need to carry the one. so you increment the other nine, and carry the one, leaving you with 00. normally, you'd just write the one you've been carrying and end up with 100, which is the correct answer. however, you only have space for two digits, so you can't continue. thus, you end up saying that 99 plus 1 equals 0.
|
||||||
|
|
||||||
|
an eight bit number has room for eight binary digits. this means that if the computer is at 11111111 (255 in decimal) and tries to add 1 again, it ends up with zero. this is called an integer overflow error - the one that the computer has been carrying has "overflowed" and spilled out, and is now lost. the number has wrapped around from 255 to 0, as if the numbers were on a loop of paper. underflow is the opposite of this problem - zero minus one is 11111111.
|
||||||
|
|
||||||
|
so if adding to the highest number possible should create zero, why does it sometimes give a negative number instead? this is due to signed integers. an unsigned integer looks like this:
|
||||||
|
7279
|
||||||
|
a signed integer looks like +628 or -216. a computer doesn't have anywhere special to put that negative (or positive) sign, so it has to use one of the bits in the number. 1111 might mean -111, for example.
|
||||||
|
|
||||||
|
(n.b. the method of signing integers described below is "offset binary". there are other methods of doing this as well, but we'll focus on this one because it's intuitive.)
|
||||||
|
|
||||||
|
if we want to represent negative numbers, we can't start at zero, because we need to be able to go lower than that. in binary, there are sixteen different possible combinations of four digits/bits, from 0000 to 1111 - zero to fifteen. instead of treating 0000 as zero, we can move zero to the halfway point between 0000 and 1111. since there are sixteen positions between these two numbers, there's no middle. (the middle between one and three is two, but there's no whole number middle between one and four.) we'll settle for choosing 1000 to be our zero, which means there are eight numbers below zero and seven numbers above it. if we treat zero as positive, we have eight negative and eight positive numbers to work with. our number range has now gone from 0 to 15, to -8 to 7. we can't count as high, but we can count lower.
|
||||||
|
|
||||||
|
in such a system, 1111 would be 7 instead of 15, just as 1000 is 0 instead of 8. when adding one to 1111, it overflows to 0000, which means -8 with our system. this is why adding to a high, positive number can produce a low, negative number. positive numbers that overflow to negative ones are signed integers.
|
||||||
|
|
||||||
|
overflow and underflow bugs are the root of many software issues, ranging from fascinating to dangerous. in the first game in sid meier's civilization series, ghandi had an aggressiveness score of 1, the lowest possible. certain political actions reduced that score by 2, which caused it to underflow and become 255 instead - far beyond the intended maximum - which gave him a very strong tendency to use nuclear weaponry. this bug was so well-known and accidentally hilarious that the company decided to intentionally make ghandi have a strong affinity for nukes in almost all the following games. some arcade games relied on the level number to generate the level, and broke when the number went above what it was expecting. (the reason behind the pac-man "kill screen" is particularly interesting!) for a more serious and worrying example of integer overflow, see this article: <https://en.wikipedia.org/wiki/Year_2038_problem> (unlike Y2K, this one is an actual issue, and has already caused numerous problems)
|
||||||
|
|
||||||
|
- {.wp-image-55}
|
||||||
|
|
||||||
|
- {.wp-image-56}
|
||||||
|
|
||||||
|
the first image is a chart explaining two methods of representing negative numbers with four bits (the one used in this post is on the left). the second is a real-world example of an "overflow".
|
||||||
|
|
||||||
|
thanks so much for reading!
|
||||||
|
|
||||||
|
[view original post](https://fedi.lynnesbian.space/@lynnesbian/101919232005592454)
|
||||||
|
|
||||||
|
|
@ -0,0 +1,23 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: What's \"defragging\"?"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech, Originally from the Fediverse]
|
||||||
|
tags: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
"defrag" is short for "defragment". when a file is saved to a hard drive, it is physically written to the device by a needle. when you need to read the file, the needle moves along the portion of the disk that contains the data to read it.
|
||||||
|
|
||||||
|
let's say you have three files on a hard drive, on a computer running windows. when you created them, windows automatically put them in order. as soon as the data for file A ends, the data for file B begins. but now you want to make file A bigger. file B is in the way, so you can't just add more to it. your computer can either
|
||||||
|
a) move file A somewhere else on the drive with more free space. this is a slow operation, and may be impossible if you don't have much free space remaining.
|
||||||
|
b) leave a note saying "the rest of the file is over here" and put the new data somewhere else.
|
||||||
|
|
||||||
|
option B is what windows will generally do. this means that over time, as you delete and create and change the size of files on your PC, they end up getting split into lots of small pieces. this is bad for performance, because the hard drive platter and needle need to do a lot more moving around to be able to read the data. if a file is in ten pieces, the needle has to move somewhere else ten times just to read that one file.
|
||||||
|
|
||||||
|
to fix this, you need to defragment your hard drive. when you do this, windows will take some time to scan the hard drive and look for the files that are split up into multiple pieces, and then it'll do its best to ensure that they end up split into as few pieces as possible. it also ensures (to some extent) that related files are next to each other - for example, it might put five files it needs to boot up right next to each other to ensure they can be found and read faster. by default, windows 10 defragments your computer weekly at 3am, but you can do it manually at any time. doing it weekly ensures that things never get too messy. leaving a hard drive's files to get fragmented for several months or even years can cause the defragmentation process to take hours.
|
||||||
|
|
||||||
|
many modern file systems use techniques to avoid fragmentation, but no hard drive based system is truly immune to this issue. this isn't a problem with SSDs, however, as they work completely differently to a hard drive.
|
||||||
|
|
||||||
|
a heavily fragmented file system will work, it'll just be slower, and might wear down the mechanisms of the hard drive a little faster. defragmentation is entirely optional, but a good idea. plus, it's always cool to watch the windows 98 defrag utility doing its thing! :mlem:
|
||||||
|
|
||||||
|
[view original post](https://fedi.lynnesbian.space/@lynnesbian/101810116855436290)
|
||||||
|
|
||||||
|
|
@ -0,0 +1,33 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: What's Keybase?"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech, Originally from the Fediverse]
|
||||||
|
tags: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
keybase is a website that allows you to prove that a given account or website is owned by you. to explain how this works, we'll need to briefly cover public key cryptography.
|
||||||
|
|
||||||
|
there are many ways to encrypt a file. one such way involves using a password to encrypt the file, which can then be decrypted using the same password. this is known as a symmetrical method, because the way it's encrypted is the same as the way it's decrypted - using a password. the underlying methods of encryption and decryption may be different, but the password remains the same. how these algorithms work is outside the scope of this post - i might make a future post about encryption.
|
||||||
|
|
||||||
|
public key encryption is asymmetrical. this means the way you encrypt it is different from the way you decrypt it. a password protected file can be opened by anyone who knows the password, but a file encrypted using this method can only be decrypted by the person you're sending it to (unless their private key has been stolen). if you encrypt a file using someone's public key, the only way to decrypt it is with their private key. since i'm the only one with access to my private key, i'm the only person who can decrypt any files that are encrypted using my public key.
|
||||||
|
|
||||||
|
my private key can also be used to "sign" a file or message to prove that i said it. anyone can verify that i was the one who signed it by using my public key. comparing the signature to any other public key won't return a match, and changing even one letter of the text will mean that the signature no longer works.
|
||||||
|
|
||||||
|
as the signing process can be used to guarantee that i said something, this means that i can use it to prove that i own, say, a particular facebook account. i could make a post saying "this is lynne" with my signature attached, and anyone could verify it using my public key. this is where keybase comes in.
|
||||||
|
|
||||||
|
the process of signing a post is rather technical, and everyone who wants to verify it will need to know where to get your public key. there are "keyservers" that contain people's public keys, but the average person won't know that, or what the long, jumbled mess of characters at the end of a message even means. keybase does this for you. after you create an account, it generates a public and private key for you to use. you don't even need to access these, it's all managed automatically. you can then verify that you own a given twitter, reddit, mastodon, etc. account by following the steps they provide to you. you just need to make a single post, which keybase will check for, compare against your public key, verify that it's you, and add to your profile. users can also download your public key and verify it themselves.
|
||||||
|
|
||||||
|
support for mastodon was only added recently and isn't quite complete yet, but it's ready to use and works well. this is why you might have noticed a lot of people talking about it recently. support for keybase is new in mastodon 2.8.
|
||||||
|
|
||||||
|
keybase can also be used to prove that you own a given website, again by making a public, signed statement. i've proven that i own lynnesbian.space with a statement here: <https://lynnesbian.space/keybase.txt>
|
||||||
|
|
||||||
|
it also provides a UI to more easily verify someone's signed message, without having to find and download their public key yourself.
|
||||||
|
|
||||||
|
keybase is built on existing and tested standards and technologies, and everything that it does can also be done yourself by hand. it just exists to make this kind of thing more accessible to the general public.
|
||||||
|
|
||||||
|
i've proven my ownership of this mastodon account ([\@lynnesbian](https://fedi.lynnesbian.space/@lynnesbian)), and you can verify that by checking my keybase page: <https://keybase.io/lynnesbian/>
|
||||||
|
|
||||||
|
keybase also offers encrypted chat and file storage, but it's main feature is that you can easily verify and confirm that you are who you say you are. so if you see a website claiming to be owned by me, and you don't see it in my keybase profile, you should be suspicious!
|
||||||
|
|
||||||
|
[view original post](https://fedi.lynnesbian.space/@lynnesbian/101939803138033541)
|
||||||
|
|
||||||
|
|
@ -0,0 +1,28 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: Why are there so few web browsers?"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech, Originally from the Fediverse]
|
||||||
|
tags: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
a web browser is a program that displays a HTML document, in the same way that a text editor is a program that displays a txt file, or a video player displays MP4s, AVIs, etc. HTML has been around for a while, first appearing around 1990.
|
||||||
|
|
||||||
|
HTML alone is enough to create a website, but almost all sites bring in CSS as well, which allows you to customise the style of a webpage, such as choosing a font or setting a background image¹. javascript (JS) is also used for many sites, allowing for interactivity, such as hiding and showing content or making web games.
|
||||||
|
|
||||||
|
together, HTML, CSS, and JS make up the foundations of the modern web. a browser that aims to be compatible with as many existing websites as possible must therefore implement all three of them effectively. some websites (twitter, ebay) will fall back to a "legacy" mode if javascript support isn't present, while others (mastodon, google maps) won't work at all.
|
||||||
|
|
||||||
|
implementing javascript and making sure it works with HTML is a particularly difficult challenge, which sets the bar for creating a new browser from scratch staggeringly high. this is partly why there are so few browsers that aren't based on firefox or chrome² that are capable of handling these lofty requirements. microsoft has decided to switch edge over to a chrome-based project, opera switched to the chrome engine years ago, and so on, because of the difficulty of keeping up. that's not to say there aren't any browsers that aren't based on firefox or chrome - safari isn't based on either of them³ - but the list is certainly sparse.
|
||||||
|
|
||||||
|
due to the difficulty of creating and maintaining a web browser, and keeping up with the ever evolving standards, bugs and oddities appear quite frequently. they often manifest in weird and obscure cases, and occasionally get reported on if they're major enough. an old version internet explorer rather famously had a bug that caused it to render certain elements of websites completely incorrectly. by the time it was fixed, some websites were already relying on it. microsoft decided to implement a "quirks mode" feature that, when enabled, would simulate the old, buggy behaviour in order to get the websites to work right. most modern browsers also implement a similar feature. this just adds yet another layer of difficulty to creating a browser.
|
||||||
|
|
||||||
|
the complexity of creating a web browser combined with the pre-existing market share domination of google chrome makes creating a new web browser difficult. this has had the effect of further consolidating chrome's market share. chrome is currently sitting about about 71.5% market share⁴, with opera (which is based on chrome) adding a further 2.4%. this means that google has a lot of say over the direction the web is headed in. google can create and implement new ways of doing things and force others to either adopt or disappear. monopolies are never a good thing, especially not over something as fundamental and universal as a web browser. at its peak, internet explorer had over 90% market share. some outdated websites still require internet explorer, which is one of the main reasons why windows 10 still includes it, despite also having edge.
|
||||||
|
|
||||||
|
[view original post](https://fedi.lynnesbian.space/@lynnesbian/101817020284110778)
|
||||||
|
|
||||||
|
footnotes:
|
||||||
|
|
||||||
|
1. before CSS, styling was done directly through HTML itself. while this way of doing things is considered outdated and deprecated, both firefox and chrome still support it for legacy compatibility. having to support deprecated standards is yet another hurdle in creating a browser.
|
||||||
|
2. chrome is the non-[free (as in freedom)](https://bune.city/2019/05/lynne-teaches-tech-what-is-free-software-why-do-people-say-software-isnt-free-even-though-you-can-download-it-for-free-from-the-app-store/) version of the open source browser "chromium", also created by google. compared to chromium, chrome adds some proprietary features like adobe flash and MP3 playback.
|
||||||
|
3. the engine safari uses is called webkit. chrome used to use this engine, but switched to a new engine based on webkit called blink. safari therefore shares at least some code with chrome.
|
||||||
|
4. based on <http://gs.statcounter.com/browser-market-share/desktop/worldwide>. note that it's impossible to perfectly measure browser market share, but this is good for getting an estimate.
|
||||||
|
|
||||||
|
|
@ -0,0 +1,19 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: Why do people say GNU/Linux or GNU+Linux?"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech, Originally from the Fediverse]
|
||||||
|
tags: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
paraphrased Wikipedia quote:
|
||||||
|
In 1991, the Linux kernel appeared. Combined with the operating system utilities developed by the GNU project, it allowed for the first operating system that was free software, commonly known as Linux.
|
||||||
|
|
||||||
|
in other words, the linux kernel and GNU utilities work together to form the linux operating system. this is why people like to say "GNU/Linux" or "GNU+Linux", to recognise the work made by the GNU projects.
|
||||||
|
|
||||||
|
however, it is possible to make a linux-based operating system based on the linux kernel. notable examples of this include alpine and android (yes, the phone operating system). this means that when you say "GNU/Linux", you aren't actually addressing all linux-based operating systems. android is not GNU/linux because it does not contain GNU software, yet it's still a linux-based operating system.
|
||||||
|
|
||||||
|
non-GNU linux operating systems are rare, but they do exist. personally, i prefer to say "linux" rather than "GNU/linux" to acknowledge the existence and (more importantly) the viability of projects such as alpine, but there are people who like to recognise GNU's contributions to the mainstream linux operating system base. both are correct. the maintainers of debian call it a "GNU/Linux distribution", while arch bills itself as a "linux distribution".
|
||||||
|
|
||||||
|
[view original post
|
||||||
|
](https://fedi.lynnesbian.space/web/statuses/101426988587606255)
|
||||||
|
|
||||||
|
|
@ -0,0 +1,22 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: Why does text on a webpage stay sharp when you zoom in, even though images get blurry?"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech, Originally from the Fediverse]
|
||||||
|
tags: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
images like PNG and JPEG files get blurry when zoomed in beyond 100% of their size. this is true of video files, too, and many other methods of representing graphics. this is because these files contain an exact description of what to show. they tell the computer what colour each point on the image is, but they only list a certain number of points (or picture elements - pixels!). if a photo is 800x600, it's 800 pixels wide, and 600 pixels tall. if you ask the computer to show it any bigger than that, it has to guess what's between those pixels. it doesn't know what the image contains - to a computer, a photo of the sky is just a bunch of blue pixels with some patches of white thrown in. there are many algorithms that a computer can use to fill in those blanks, but in the end, it's just an estimation. it won't be able to show you any more detail than the regular version could.
|
||||||
|
|
||||||
|
a font, however, is different. almost all fonts on a modern computer are described in a vector format. rather than saying "this pixel is black, this one is white", they say "draw a line from here to here". a list of instructions can be done at any size. if you ask a computer to show an image of a triangle, it'll get blurry when you zoom in. but if you teach it how to draw a triangle, and then tell it to make it bigger, it can "zoom in" forever without getting blurry. there's no pixels or resolution to worry about.
|
||||||
|
|
||||||
|
vectors can also be used for images, such as the SVG format. here's an example of one on wikipedia: <https://upload.wikimedia.org/wikipedia/commons/0/02/SVG_logo.svg>
|
||||||
|
even though it's an image, you can zoom in without it ever getting blurry!
|
||||||
|
|
||||||
|
even though you can resize an SVG to your heart's content, it'll never reveal more detail that what it was created with. so you can't "zoom and enhance" a vector image either.
|
||||||
|
|
||||||
|
there are always exceptions to the rule. not all fonts use vector graphics - some use bitmap graphics, and they get blurry like PNGs and JPEGs do too.
|
||||||
|
|
||||||
|
so if vector graphics don't get blurry, why don't we use them for photos? to put it simply, making a vector image is hard. you need to describe every stroke and shape and colour that goes in to replicating the drawing. this gets out of hand very quickly when you want to save images of complex scenery (or even just faces). cameras simply can't do this on the fly, and even if they could, the resultant file would be an enormous mess of assumptions and imperfections. the current method of doing things is out best option.
|
||||||
|
|
||||||
|
[view original post](https://fedi.lynnesbian.space/@lynnesbian/101942900073557509)
|
||||||
|
|
||||||
|
|
@ -0,0 +1,23 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: why don't windows programs work on a mac, and vice versa?"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech, Originally from the Fediverse]
|
||||||
|
tags: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
an operating system (OS), such as windows or macOS, handles a lot of low-level stuff. this means that developers don't have to worry about details like "how to scroll a page" or "how to read text from a file", because the OS handles it for you. a computer can't do anything without an OS - it's needed for even the most basic tasks.
|
||||||
|
|
||||||
|
the OS provides you with a huge amount of functions you can call to get stuff done. rather than worrying about the fundamentals of reading a file from a hard drive, the OS will provide you with a function that does the job for you. however, every OS does this differently. this means that you can't just run windows program on macOS because the functions it needs aren't there.
|
||||||
|
|
||||||
|
[wine](https://www.winehq.org/) is a program that translates windows functions into ones that work with macOS or linux. this allows you to actually run windows programs on macOS. when the program asks for a windows function, wine performs the macOS equivalent and pretends it's running on windows. the macOS version of the sims 3 actually runs in a modified version of wine - it's the exact same as the windows version, just with a wine "wrapper" around it.
|
||||||
|
|
||||||
|
it's possible to make programs that work on windows, macOS, and linux. for example, games made with the engine "unity" can run on all three of these. however, the actual game file is still different for all three - unity just translates the code into versions that work \*individually\* with windows, macOS, or linux. this means that you can't run a windows version of a unity game on macOS.
|
||||||
|
|
||||||
|
a java program can run fine on all three of the above operating systems, but you actually have to install java first - and the installer is specific to your OS. it's not possible to make a program that truly works with all three of these operating systems from a single file with no installers or engines or other behind the scenes work, as the differences are simply too great.
|
||||||
|
|
||||||
|
one more interesting note: [reactOS](https://www.reactos.org/) is an operating system based on wine technology. its goal is to completely simulate windows without actually using any windows code (as this is illegal) by using the same methods wine does. it's still in alpha, but it's really cool!
|
||||||
|
|
||||||
|
(i know there are other operating systems, i just didn't mention them for brevity's sake. sorry \*BSD people.)
|
||||||
|
|
||||||
|
[view original post](https://fedi.lynnesbian.space/web/statuses/101786030032344976)
|
||||||
|
|
||||||
33
_posts/lynne-teaches-tech/2019-05-05-lynne-teaches-tech.md
Normal file
33
_posts/lynne-teaches-tech/2019-05-05-lynne-teaches-tech.md
Normal file
|
|
@ -0,0 +1,33 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: Why does compressing a JPEG make it look worse, even though putting in a ZIP file makes it look the same?"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech, Originally from the Fediverse]
|
||||||
|
tags: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
there are many different methods of file compression. one of the simplest methods is run length encoding (RLE). the idea is simple: say you have a file like this:
|
||||||
|
`aaabbbbaaaaa`
|
||||||
|
you could store it as:
|
||||||
|
`a3b4a5`
|
||||||
|
to represent that there are 3 a's, 4 b's, etc. you would then simply need a program to reverse the process - decompression. this is seldom used, however, as it had a fairly major flaw:
|
||||||
|
`abcde`
|
||||||
|
becomes
|
||||||
|
`a1b1c1d1e1`
|
||||||
|
which is twice as large! RLE compression is best used for data with lots of repetition, and will generally make more random files \*larger\* rather than smaller.
|
||||||
|
|
||||||
|
a more complex method is to make a "dictionary" of things contained in the file and use that to make things smaller. for example, you could replace all occurrences of "the united states of america" with "🇺🇸", and then state that "🇺🇸" refers to "the united states of america" in the dictionary. this would allow you to save a (relatively) huge amount of space if the full phrase appears dozens of times.
|
||||||
|
|
||||||
|
what i've been talking about so far are lossless compression methods. the file is exactly the same after being compressed and decompressed. lossy compression, on the other hand, allows for some data loss. this would be unacceptable in, for example, a computer program or a text file, because you can't just remove a chunk of text or code and approximate what used to be there. you can, however, do this with an image. this is how JPEGs work. the compression is lossy, which means that some data is removed. this is relatively imperceptible at higher quality settings, but becomes more obvious the more you sacrifice quality for size. PNG files are (almost always) lossless, however. your phone camera takes photos in JPEG instead of PNG, though, because even though some quality is lost, a photo stored as a PNG would be much, much larger.
|
||||||
|
|
||||||
|
some examples of file formats that typically use lossy compression are JPEG, MP4, MP3, OGG, and AVI. some examples of lossless compression formats are FLAC, PNG, ZIP, RAR, and ALAC. some examples of lossless, uncompressed files are WAV, TXT, JS, BMP, and TAR. in terms of file size, you'll always find that lossy files are smaller than the lossless files they were created from (unless it's an horrendously inefficient compression format), and that losslessly compressed files are smaller than uncompressed ones.
|
||||||
|
|
||||||
|
you'll find that putting a long text file in a zip makes it much smaller, but putting an MP3 in a zip has a much less major effect. this is because MP3 files are already compressed quite efficiently, and there's not really much that a lossless algorithm can do.
|
||||||
|
|
||||||
|
there are benefits to all three types of formats. lossily compressed files are much smaller, losslessly compressed files are perfectly true to the original sound/image/etc while being much smaller, and uncompressed data is very easy for computers to work with, as they don't have to apply any decompression or compression algorithms to it. this is (partly) why BMP and WAV files still exist, despite PNG and FLAC being much more efficient.
|
||||||
|
|
||||||
|
as an example of how dramatic these differences often are, i looked at the file sizes for the downloadable version of master boot record's album "internet protocol" in three formats: WAV, FLAC, and MP3.
|
||||||
|
|
||||||
|
{.wp-image-45}
|
||||||
|
|
||||||
|
you can see that the file size (shown in megabytes) is nearly 90 megabytes smaller with the FLAC version, and the MP3 version is only \~13% of the size of the WAV version. note that these downloads are in ZIP format - the WAV files would be even larger than shown here. this is not representative of all compression algorithms, nor is it representative of all music - this is just an illustrative example. TV static in particular compresses very poorly, because it's so random, which makes it hard for algorithms to find patterns. watch a youtube video of TV static to see this in effect - you'll notice obvious "block" shapes and blurriness that shouldn't be there as the algorithm struggles to do its job. the compression on youtube is particularly strong to ensure that the servers can keep up with the enormous demand, but not so much so that videos become blurry, unwatchable messes.
|
||||||
|
|
||||||
|
|
@ -0,0 +1,22 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: Why did everyone's Firefox add-ons get disabled around May 4th?"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech]
|
||||||
|
tags: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
Mozilla, the company behind Firefox, have implemented a number of security checks in their browser related to extensions. One such check is a digital certificate that all add-ons must be signed with. This certificate is like a [HTTPS certificate](https://bune.city/2019/05/lynne-teaches-tech-what-does-https-mean/) - the thing that gives you a green padlock in your browser's URL bar.
|
||||||
|
|
||||||
|
You've probably seen a HTTPS error before. This happens when a site's certificate is invalid for one reason or another. One such reason is that the certificate has expired.
|
||||||
|
|
||||||
|
<!--more-->
|
||||||
|
HTTPS certificates are only valid for a certain amount of time. When that time runs out, they need to be renewed. This is done to ensure that the person with the certificate is still running the website, and is still interested in keeping the certificate.
|
||||||
|
|
||||||
|
{.wp-image-142}
|
||||||
|
|
||||||
|
When a certificate expires, your browser will refuse to connect to the website. A similar issue happened with Firefox - their own add-on signing certificate expired on the 4th of May, 00:09 UTC, [causing everyone's add-ons to be disabled](https://support.mozilla.org/en-US/kb/add-ons-disabled-or-fail-to-install-firefox) after that timed passed.
|
||||||
|
|
||||||
|
One would think that Firefox wouldn't disable an add-on that had been signed with a certificate while it was still valid, but apparently they didn't do that. Even so, this could have been avoided if anybody had remembered to renew the certificate, which nobody did. This is a particularly embarrassing issue for Firefox, especially considering both how easily it could have been avoided and the fact that it really shouldn't have been possible for this to happen in the first place. It also raises the question: What happens if Mozilla disappears, and people keep using Firefox? Thankfully, there are ways to disable extension signing, which means that you can protect yourself from ever happening again, but note that **doing this is a minor security risk**.
|
||||||
|
|
||||||
|
One could argue that by remotely disabling some of the functionality of your browser, intentionally or not, Mozilla is violating the [four essential freedoms](https://fsfe.org/freesoftware/basics/4freedoms.en.html), specifically, the right to unlimited use for any purpose.
|
||||||
|
|
||||||
|
|
@ -0,0 +1,64 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: What are all the different types and versions of USB about?"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech]
|
||||||
|
tags: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
Describing something like an Ethernet port is easy. You have one number to worry about: the speed rating. 100Mbps, 1Gbps, 10Gbps... It's very simple.
|
||||||
|
|
||||||
|
USB, on the other hand, has two defining attributes: the type, and the version. Calling a USB port "USB 3.1" or "USB-C" doesn't tell you the whole story.
|
||||||
|
|
||||||
|
<!--more-->
|
||||||
|
*Note: I'll be using the term "port" to mean "bus" at times throughout this post for simplicity's sake.*
|
||||||
|
|
||||||
|
The letters
|
||||||
|
-----------
|
||||||
|
|
||||||
|
At first, there really was only one USB port type.
|
||||||
|
|
||||||
|
{.wp-image-202}
|
||||||
|
|
||||||
|
When people describe a port as a "USB port" without any additional info, they're talking about this one. USB-A ports can be found everywhere, and are (as of writing) still more common than USB-C.
|
||||||
|
|
||||||
|
If this is USB-A, and we're up to USB-C, then where's USB-B? You might have used one without knowing.
|
||||||
|
|
||||||
|
{.wp-image-203}
|
||||||
|
|
||||||
|
USB-B cables are often referred to as "printer cables", as they are most commonly used on printers.
|
||||||
|
|
||||||
|
{.wp-image-204}
|
||||||
|
|
||||||
|
A more commonly seen port is USB Micro-B, which was used on most Android smartphones, before manufacturers adopted USB-C.
|
||||||
|
|
||||||
|
{.wp-image-205}
|
||||||
|
|
||||||
|
There are [many more varieties of USB](https://en.wikipedia.org/wiki/USB#Receptacle_(socket)_identification), such as USB Mini-A, USB SuperSpeed B, and, of course, USB-C.
|
||||||
|
|
||||||
|
{.wp-image-207}
|
||||||
|
|
||||||
|
The numbers
|
||||||
|
-----------
|
||||||
|
|
||||||
|
USB 1.0 offered transfer rates of up to 1.5 Mbits per second, and future versions improved upon that speed. A USB 3.0 port can (theoretically) reach speeds of up to 5 Gbits/s. A USB-C port can implement USB 3.0 or later, which is where the issue lies.
|
||||||
|
|
||||||
|
Describing a given port as USB-C doesn't tell you the speed it operates at, and describing a port as USB 3.1 doesn't tell you what type it is. The original USB port with the lowest version - the original port that debuted in '96 - is not just a USB port, it's a USB-A 1.0 port.
|
||||||
|
|
||||||
|
To make matters worse
|
||||||
|
---------------------
|
||||||
|
|
||||||
|
[Thunderbolt 3](https://en.wikipedia.org/wiki/Thunderbolt_(interface)#Thunderbolt_3) is a standard that uses the USB-C port. It allows for (among other things) communicating with an external GPU and connecting external displays. Thus, when describing a USB-C port, it is *also* pertinent to note whether or not it has Thunderbolt support. This doesn't apply to non-C ports (yet!).
|
||||||
|
|
||||||
|
Recap
|
||||||
|
-----
|
||||||
|
|
||||||
|
The letter (USB-**A**, USB-**C**) refers to the type of connector. You **cannot** mix and match types (a USB-C device will not connect to a USB-B port).
|
||||||
|
|
||||||
|
The number (USB **3.1**, USB **2.0**) refers to the version number. You **can usually** mix and match version numbers, but you may encounter reduced performance or functionality.
|
||||||
|
|
||||||
|
Thunderbolt is an **optional extension** for USB-C ports. A Thunderbolt device cannot work with a non-Thunderbolt port, but a non-Thunderbolt device will work with a Thunderbolt port.
|
||||||
|
|
||||||
|
There's more that I didn't go into in this post, but if I wanted to describe the ins and outs of every USB specification, we'd be here forever! :mlem:
|
||||||
|
|
||||||
|
*Some of the images used in this article were created by Wikipedia user* *[Fred the Oyster](https://commons.m.wikimedia.org/wiki/User:Fred_the_Oyster), under the* *[CC-BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/)* *license.*
|
||||||
|
|
||||||
|
|
@ -0,0 +1,20 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: Why does Windows need to restart to install updates so often?"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech]
|
||||||
|
tags: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
There are many different system files that Windows needs in order to function. These files are often updated using Windows Update to add new features, fix bugs, patch security issues, and more.
|
||||||
|
|
||||||
|
Windows is unable to replace these files while they're in use. This is for numerous reasons, both technical and practical.
|
||||||
|
|
||||||
|
<!--more-->
|
||||||
|
If an update specifies that file X needs to be replaced, and file X is being used by a critical system process, then we have an issue. Closing the critical process would cause Windows to stop working, which is obviously unacceptable behaviour. There's no way to switch the old version of file X with the new one while the critical process is running, but Windows needs that process.
|
||||||
|
|
||||||
|
The only way to safely stop the critical process is to restart Windows. Updates can either be applied before or after you restart. Windows will ensure that the critical process isn't running yet, replace file X, and then start up normally. Windows can't start up properly until the new version of file X is in place, so you can't use Windows while it's updating.
|
||||||
|
|
||||||
|
Not all updates require a restart. Windows Vista introduced [a feature](https://devblogs.microsoft.com/oldnewthing/?p=92501) that allows system files to be replaced while the system is running under certain conditions. If an update replaces a non-critical file, or a file your computer isn't using, it's not necessary to restart.
|
||||||
|
|
||||||
|
Unix-based systems like macOS and Linux don't need to reboot as often, due to the way they handle loading files. In short, Unix systems load critical files in memory and don't depend on the version on the hard drive, while Windows depends on the files on the hard drive staying the same. If a critical file on Linux needs to be updated, the system will simply swap the old version with the new one while running. Currently running processes will use the old version, but new processes will use the new file. Replacing certain files still requires rebooting. This does, however, pose a security risk, and rebooting to ensure the new files are loaded is still recommended, even if it's not technically required.
|
||||||
|
|
||||||
|
|
@ -0,0 +1,42 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: Does \"dark mode\" really save battery life?"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech]
|
||||||
|
tags: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
It depends!
|
||||||
|
|
||||||
|
<!--more-->
|
||||||
|
Right now, there are two common types of consumer-oriented display technologies: LCD, and OLED (including AMOLED). LCD screens won't save any battery life by using dark themes, while OLED ones do.
|
||||||
|
|
||||||
|
LCD
|
||||||
|
---
|
||||||
|
|
||||||
|
Consumer electronics with LCD displays use LED backlights to give the image brightness. You may sometimes see LCD displays referred to as "LED-LCD", or (mistakenly) "LED". The LED provides the backlight, while the LCD displays the picture. It's possible to have an LCD display without a backlight (the Gameboy and Gameboy Colour had one), but uncommon.
|
||||||
|
|
||||||
|
The LED backlight provides brightness to the whole LCD display at once. To light up even one pixel, the whole display needs to be lit up. There's no way to have only some areas bright and others dark, it's all or nothing. Issues like backlight bleeding are inherent to this approach, and "true black" can never be displayed, as the display is always emitting light.
|
||||||
|
|
||||||
|
 (CC-BY-SA)](https://wasabi.lynnesbian.space/bune-city/2019/05/e8e7ccf342b1fe4471e82df0a2432578/8238692078_4261f57902_k.jpg){.wp-image-304}
|
||||||
|
|
||||||
|
Colour is irrelevant to power saving on an LCD display. The only thing that helps is turning down the brightness. Displaying black at full brightness uses much more power than displaying white at low brightness, even though the white screen would provide much more light. The LCD filters out the blacklight to provide black, but the backlight's still on.
|
||||||
|
|
||||||
|
However, LCD displays tend to be more power efficient when displaying bright images than OLED displays. As soon as you start turning down the brightness, though, OLED quickly pulls ahead.
|
||||||
|
|
||||||
|
OLED
|
||||||
|
----
|
||||||
|
|
||||||
|
OLED displays don't have backlights. Every pixel is individually lit, so making half the screen black would use (about) half the power. Because of this, dark themes really do save power on OLED displays. Darker colours mean less power usage, and i a pixel is completely black (pure black, no light at all), it will turn off. A dark theme with a pure black background saves much, much more power than a dark grey background, because it allows the pixels to turn off entirely.
|
||||||
|
|
||||||
|
There's a downside to this, however - the pixels can't be turned on instantly. If you're scrolling quickly down a page with a pure black background on an OLED device, you might notice subtle "[smears](https://youtube.com/watch?v=QskpJDvA7zc&t=7s)" caused by the pixels taking some time to turn on. This effect is hard to notice in most cases, but is still something to consider.
|
||||||
|
|
||||||
|
The colour can also affect the battery usage. Google [gave a real world example](https://youtube.com/watch?v=N_6sPd0Jd3g) of battery usage with various colours on their 2016 Pixel phone:
|
||||||
|
|
||||||
|
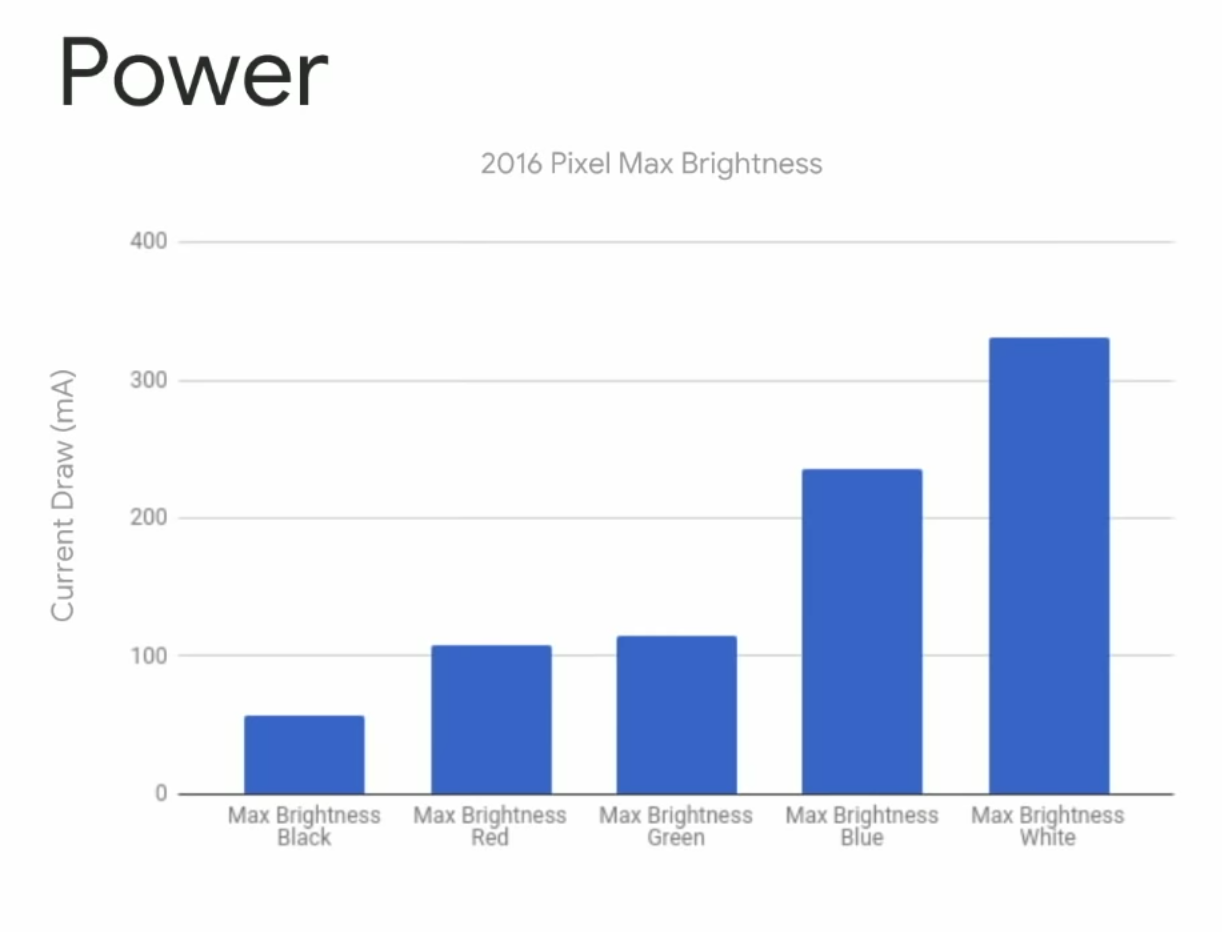{.wp-image-308}
|
||||||
|
|
||||||
|
Summary
|
||||||
|
-------
|
||||||
|
|
||||||
|
Dark themes don't make a difference to power consumption on an LCD display, although you may find them easier on the eyes. While LCD displays light up the entire display at once with a backlight, OLED displays can set the brightness individually for each pixel, meaning that mostly black images use less power.
|
||||||
|
|
||||||
|
|
@ -0,0 +1,12 @@
|
||||||
|
---
|
||||||
|
title: "Ask your own Lynne Teaches Tech question!"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Announcements]
|
||||||
|
---
|
||||||
|
|
||||||
|
If you've always wanted to see your own question answered by a [Lynne Teaches Tech](https://bune.city/tag/lynne-teaches-tech) post, there's now an easy survey to fill out to submit a question!
|
||||||
|
|
||||||
|
The survey can be completed [here](https://l.bune.city/ltt-survey). The only info that's collected is your response!
|
||||||
|
|
||||||
|
You can also just send [me](https://l.bune.city/me) a message on the Fediverse, or leave a comment on a blog post. This method is anonymous, however, so you might prefer that.
|
||||||
|
|
||||||
|
|
@ -0,0 +1,77 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: What is the Linux kernel?"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech]
|
||||||
|
tags: [Lynne Teaches Tech, Reader Question]
|
||||||
|
---
|
||||||
|
|
||||||
|
Our first survey question! The submitted question asked:
|
||||||
|
|
||||||
|
- What is the Linux kernel?
|
||||||
|
- Why does apt make me install a new one every month or so?
|
||||||
|
- Why do the old ones stick around and waste space?
|
||||||
|
|
||||||
|
<!--more-->
|
||||||
|
We'll be answering all three of these questions. Let's start with the first one.
|
||||||
|
|
||||||
|
What is the Linux kernel?
|
||||||
|
-------------------------
|
||||||
|
|
||||||
|
The kernel is the underlying part of a computer that makes all the low level stuff work. Things like reading files, managing which programs are running, and keeping track of memory usage are handled by the kernel.
|
||||||
|
|
||||||
|
Almost every operating system has a kernel - Windows uses the NT kernel, macOS uses the XNU kernel, and Linux distributions (including Android!) use the Linux kernel.
|
||||||
|
|
||||||
|
The kernel handles communication between the software running on your computer and the hardware your computer is made with, so you won't get far without it. This also means you can't swap it out while your computer's running, so if you update the kernel using apt (or otherwise), you'll need to restart afterwards, even if the computer doesn't tell you to (or force you to).
|
||||||
|
|
||||||
|
*Note: There are methods of replacing the Linux kernel while the system is still running, but that is beyond the scope of this post.*
|
||||||
|
|
||||||
|
When the kernel encounters a critical failure that it can't recover from, your computer will stop working. On Windows computers, this is known as a stop error, and when a stop error occurs, Windows will display...
|
||||||
|
|
||||||
|
{.wp-image-317}
|
||||||
|
|
||||||
|
This happens (much less frequently) on Linux systems too, with a much less visually appealing (although more informative, if you're able to understand what it's talking about) error screen.
|
||||||
|
|
||||||
|
*\],* [*via Wikimedia Commons*](https://commons.wikimedia.org/wiki/File:Ubuntu-linux-kernel-panic-by-jpangamarca.JPG)](https://wasabi.lynnesbian.space/bune-city/2019/05/6f98ec43db35f624cd5dc67e9e69a3df/Ubuntu-linux-kernel-panic-by-jpangamarca-1024x768.jpg){.wp-image-320}
|
||||||
|
|
||||||
|
So now we know what a kernel is and does - it's a piece of software that allows other software to communicate with your computer's hardware, and it's critical to everything working.
|
||||||
|
|
||||||
|
Why do I need to update the kernel so often?
|
||||||
|
--------------------------------------------
|
||||||
|
|
||||||
|
This is because the Linux kernel is updated very often. There's work being done all the time to improve security, fix bugs, improve hardware support, and more. As of the time of writing, the latest kernel version is 5.x. You can see a list of update logs [here](https://cdn.kernel.org/pub/linux/kernel/v5.x/) - notice how short the times between each changelog are.
|
||||||
|
|
||||||
|
Most Linux distributions (including Ubuntu) won't receive every single one of these versions. There's so many of them, and many only introduce minor changes. Additionally, the Ubuntu developers need to make sure that everything works properly with the new kernel version, so it won't be available right away.
|
||||||
|
|
||||||
|
You can check the Linux kernel you're running with the command `uname -r`, and you can check the latest version at [kernel.org](https://www.kernel.org/).
|
||||||
|
|
||||||
|
This doesn't answer why the kernel is updated so frequently, though.
|
||||||
|
|
||||||
|
This is because there are [many, many changes](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/log/) made to the Linux kernel every single day, by a wide range of contributors across the world. Not every single update gets its own version number, though. With the high frequency of changes made, there are understandably many updates released in a month. Every now and then, the Ubuntu developers will pick one of these versions, work on testing it to ensure it's compatible with the rest of Ubuntu, and then release it for you to download.
|
||||||
|
|
||||||
|
Why do the old versions stick around?
|
||||||
|
-------------------------------------
|
||||||
|
|
||||||
|
This requires a more in-depth explanation of how your system handles kernel updates. I'll be talking about Ubuntu specifically here, but almost all of this applies to other Debian-based distributions too.
|
||||||
|
|
||||||
|
Even with the testing done by Ubuntu, it's impossible to know that a new kernel release will work with every single Ubuntu user on Earth. To make sure you still have a working computer at the end of the day, Ubuntu will keep the previous version of the kernel installed. If you restart, and the new kernel doesn't work properly, you can switch back to the old kernel to have a working PC.
|
||||||
|
|
||||||
|
The Ubuntu developers tend to keep older versions of the kernel around as separate packages. When your computer tries to install the Linux kernel image (`linux-image-generic`), apt will tell it which particular version it needs to install.
|
||||||
|
|
||||||
|
 currently depends on the `linux-image-4.15.0-50-generic` package.](https://wasabi.lynnesbian.space/bune-city/2019/05/cc12efadbe0926d401b7ccfa930ed65d/image.png){.wp-image-321}
|
||||||
|
|
||||||
|
This means that you only ever have to install `linux-image-generic` and the system will automatically install the correct kernel version for you.
|
||||||
|
|
||||||
|
You can see how many kernel versions Ubuntu Bionic currently has available by checking [this page](https://packages.ubuntu.com/source/bionic/linux-signed).
|
||||||
|
|
||||||
|
apt will never remove a package without your permission. If a package is no longer required, you need to remove it manually by running `sudo apt autoremove`. This will clean up any packages that aren't currently in use, including older Linux kernels.
|
||||||
|
|
||||||
|
You'll notice that `uname -r` will give you the same result before and after updating the kernel. Even though the new kernel update was *installed*, it's not *active* yet. You need to restart your computer to start using the new kernel version.
|
||||||
|
|
||||||
|
So, in short: to get rid of those old, unused kernel versions, try rebooting (to make sure you're running the latest kernel), then run `sudo apt autoremove`.
|
||||||
|
|
||||||
|
Summary
|
||||||
|
-------
|
||||||
|
|
||||||
|
The Linux kernel is a critical piece of your computer's software. Without it, nothing will work, and if it crashes, the whole system comes down with it. It can't be updated without a reboot. New versions are frequently releases, and the Ubuntu team tests and releases a new version once every month or so. Ubuntu keeps old versions around for various reasons, but you can get rid of the ones you aren't using fairly easily.
|
||||||
|
|
||||||
|
|
@ -0,0 +1,98 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: What are protocols and formats? How do they come to be?"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech]
|
||||||
|
tags: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
This question, like [our last reader-submitted question](https://bune.city/2019/05/lynne-teaches-tech-what-is-the-linux-kernel/), is in three parts:
|
||||||
|
|
||||||
|
- What exactly is a protocol?
|
||||||
|
- What exactly is a format?
|
||||||
|
- Can you give a short rundown of how standardisation in IT works?
|
||||||
|
|
||||||
|
I'll answer them from top to bottom.
|
||||||
|
|
||||||
|
<!--more-->
|
||||||
|
Protocols
|
||||||
|
---------
|
||||||
|
|
||||||
|
*Update 27/05/19: Corrected a statement about binary files being unreadable by humans.*
|
||||||
|
|
||||||
|
Protocols are used to facilitate communication between computers. You need rules for what things mean and how to behave, otherwise your computer won't know what to do with all the data it's receiving.
|
||||||
|
|
||||||
|
For the sake of the explanation, we'll create our own fake protocol, ETP: Face Transfer Protocol. You can use this protocol to send an emoji from one networked computer to another.
|
||||||
|
|
||||||
|
A proper ETP communication will have two pieces of information: An emoji, and a date the emoji was sent. When you connect your ETP client to an ETP server, you might receive this:
|
||||||
|
|
||||||
|
``` {.wp-block-code}
|
||||||
|
Emoji: 🍔
|
||||||
|
Date: 2019-05-23 10:31:45
|
||||||
|
```
|
||||||
|
|
||||||
|
Your ETP client can then format this raw data into something more readable.
|
||||||
|
|
||||||
|
> 🍔
|
||||||
|
>
|
||||||
|
> <cite>Received on May 23rd at 10:31 AM from etp://bune.city</cite>
|
||||||
|
|
||||||
|
This isn't a very useful protocol, but it gets the point across: A protocol allows computers to communicate using a predefined set of rules.
|
||||||
|
|
||||||
|
The client can treat this ETP data however it wants. It can show just the emoji, or just the date, or maybe it tells your printer to make 100 copies of the emoji. The ETP server doesn't tell the client what to do with the data, it just sends the data. Your client might even send a response back.
|
||||||
|
|
||||||
|
A real world example is HyperText Transfer Protocol, or HTTP. To view this blog post, your computer sent a HTTP request, specifying that you want to view this particular page. The server then sent the page back, including some additional info, such as the size of the response, the encoding (such as `text/html`), the date it was last modified, and so on. The only information you end up seeing is the content - your web browser handled the rest.
|
||||||
|
|
||||||
|
HTTPS works the same way as HTTP in this regard. It's the same protocol with encryption added, and otherwise behaves the same.
|
||||||
|
|
||||||
|
Formats
|
||||||
|
-------
|
||||||
|
|
||||||
|
Formats are ways to store types of data on a computer. There are formats for documents (.docx, .pdf, .odt...), audio (.mp3, .ogg, .flac...) and so on. Documents are sort of similar to protocols in that they describe data to be interpreted. The main difference is that protocols work over a network, and formats are files. You can transfer files between computers using protocols, but you can't use a format to transfer a file. You also can't store a protocol as a file, because protocols are conversational - your computer needs to be able to talk to a HTTP file. You can, however, run a server on your computer to make and respond to HTTP requests.
|
||||||
|
|
||||||
|
Let's invent a simple format, a .face file. A .face file looks like this:
|
||||||
|
|
||||||
|
``` {.wp-block-code}
|
||||||
|
>>>Face file version 1<<<
|
||||||
|
:)
|
||||||
|
```
|
||||||
|
|
||||||
|
The first line lets the face file reader know that it's definitely reading a face file. The second line is the actual face. The first line appears in every single face file, and the second line changes between files. Another example would be:
|
||||||
|
|
||||||
|
``` {.wp-block-code}
|
||||||
|
>>>Face file version 1<<<
|
||||||
|
:(
|
||||||
|
```
|
||||||
|
|
||||||
|
While some files are easily readable by opening them with a text editor, such as with our .face file, others are unreadable messes of binary information. To read these types of files, a file viewer is always needed. While our face file can be understood without a viewer, we're still going to create a viewer to demonstrate how information can be made to look nicer and more human-readable with the assistance of a program. Having a computer parse and display the information in a nicer format can make viewing a file a much better experience.
|
||||||
|
|
||||||
|
Let's call our face file viewer FacesTime, because I'm uncreative. When you tell FacesTime to open a file, it first checks to make sure the first line is there. If it is, it assumes it's looking at a genuine face file, and reads on.
|
||||||
|
|
||||||
|
It then gets to the second line, which is the data portion. FacesTime takes this previously unreadable `:)` and converts it into a human readable version, as demonstrated by the highly realistic mockup below.
|
||||||
|
|
||||||
|
{.wp-image-330}
|
||||||
|
|
||||||
|
Some formats are more flexible than others. Our .face format could be displayed as an emoji, or a drawing, or even a photo. When you have something like an audio file, however, there's not much room for interpretation. You can change things like contrast and colour balance, but you obviously want the actual sound to remain unchanged. On the other hand, you could have a program that opens the file and displays a visualised version instead of playing the song, or a program that lets you edit the song title and album art without actually playing it. You can do what you want with formats, but most of the time, you just want to display the content of it in a human-readable (or listenable!) way.
|
||||||
|
|
||||||
|
A .txt file specifies nothing but the raw text inside it, meaning that you're free to interpret it however you want. Your viewer can choose the font size, colour, and so on. However, a Word document is a different story. You could, of course, create a Word document viewer that always displayed text as Comic Sans, but then you wouldn't have a very good document viewer. It's usually best to just follow the standard, because everyone else is following it, too.
|
||||||
|
|
||||||
|
How are standards created?
|
||||||
|
--------------------------
|
||||||
|
|
||||||
|
Anyone can create a standard. I created two just then: The ETP protocol, and the .face format. I didn't really define them very well, but I did define them to some extent. Someone could create an ETP server right now with the information provided. However, what actually happens with my standards is beyond my control. Someone could create an ETP server that allows for more than one emoji at a time. A text format could have a standard saying "all text must be displayed as hot pink on neon green", but nobody actually has to follow that. It's different if there's a certification process, however.
|
||||||
|
|
||||||
|
To display a DVD Video label, a DVD player must comply with the DVD standard. If it does anything differently (such as playing all the video upside down), it doesn't get approved, and can't display the label. Again, there's nothing stopping you from creating such a player, and if you don't care about having the DVD Video label applied to your product (or being allowed to call your product a "DVD player"), then you're good to go.
|
||||||
|
|
||||||
|
In the end, standards are just a guideline. Things will typically go badly if you don't follow them, but you don't have to, and sometimes you might want to violate them on purpose. An example is our .face format - you might want to violate the standard by including multiple faces. However, any standard .face file viewer wouldn't be able to understand your modified version, so unless everyone agrees on *your* standard, then things probably won't work out too well.
|
||||||
|
|
||||||
|
Summary
|
||||||
|
-------
|
||||||
|
|
||||||
|
A protocol defines a method of communication for two computers to "talk" to each other. A format defines a method for one computer to read and display data. Standards can be created by anyone, and are occasionally enforced.
|
||||||
|
|
||||||
|
Thanks for reading!
|
||||||
|
|
||||||
|
``` {.wp-block-code}
|
||||||
|
Emoji: 😀
|
||||||
|
Date: 2019-05-24 00:45:18 AEST
|
||||||
|
```
|
||||||
|
|
||||||
|
|
@ -0,0 +1,78 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: What do all the components of a computer mean?"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech, Originally from the Fediverse]
|
||||||
|
tags: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
*This is a revised version of* [*this post*](https://fedi.lynnesbian.space/@lynnesbian/101544435256951090)*.*
|
||||||
|
|
||||||
|
If you're buying a computer or laptop or even a phone, there's a lot of jargon that might confuse you to look out for. It ranges from straightforward statistics to obscure facts to annoying "gotcha"s. This post aims to break them down.
|
||||||
|
|
||||||
|
<!--more-->
|
||||||
|
The Fundamentals
|
||||||
|
----------------
|
||||||
|
|
||||||
|
### CPU
|
||||||
|
|
||||||
|
The central processing unit. This is what your computer uses to crunch numbers, and the benefits of a fast CPU can be seen everywhere from decompressing a large zip file to processing a heavy webpage to converting an AVI to an MP4. A slow CPU can make an otherwise good computer into a laggy, unresponsive mess.
|
||||||
|
|
||||||
|
We measure CPU performance in terms of instructions per second and cores. Instructions per second are measured in hertz, for example, 3.2GHz. One hertz is one instruction per second, so a 4KHz CPU can complete four thousand instructions per second. Instructions are very, very basic steps for a computer to do - think "add two numbers", not "open this file". The more instructions your computer can do per second, the faster it'll be.
|
||||||
|
|
||||||
|
Cores represent how many tasks your computer can work on at once. For example, if your video editor is using 100% CPU on your single-core machine, your computer will be unusable, but if you have more cores, you'll still have spare power, even when one of the cores is maxed out. Many modern apps, such as Chrome and Discord, take advantage of multiple cores by dedicating groups of tabs to each core.
|
||||||
|
|
||||||
|
"Hyperthreading" is an Intel technology that allows a CPU to act like it has more cores than it actually has, for example, a quad-core CPU with hyperthreading would be used as if it was an octo-core. The way this works is kinda complex, and I don't want to make this post too long.
|
||||||
|
|
||||||
|
### RAM
|
||||||
|
|
||||||
|
Also called memory, and not the same thing as storage. Memory is a measure of how much stuff your computer can do at once. When you open a document, picture, video, song, etc., some or all of it is loaded into memory. This is because memory is much, much faster than a hard drive or SSD. If you don't have enough memory, Windows (or macOS, or what have you) will start chugging along and apps will start crashing as they all fight over the scraps. You can mitigate this somewhat by creating a swap file on your hard drive, which will be used as supplementary memory, but then you lose the speed benefits, and waste storage space.
|
||||||
|
|
||||||
|
### Storage
|
||||||
|
|
||||||
|
HDD, SSD, SSHD, hybrid drive, hard drive, hard disk, solid state drive, Optane… All of these mean the same thing: storage. The more storage you have, the more files you can save. If you run out of storage, things start going badly, as your computer always needs a little spare storage to work with. Everything you download or install or save uses storage space.
|
||||||
|
|
||||||
|
So why are there all these different names? As technology marches on, we invent better methods for doing things, including storage. Hard drives are slow and inefficient (they're one of the few parts of a modern computer that are still mechanical), but much cheaper than SSDs. SSDs work like a flash drive (aka usb stick, thumb drive…) and thus avoid the speed issues of a conventional hard drive. Hard drives need to be defragmented because as you create and delete files, they get ordered poorly, and it takes longer to access them, because the magnetic platter needs to spin more for the needle to read the files (yes, this is actually how hard drives work). With an SSD, however, there's no needle or platter, and files can be accessed "out of order" much more easily.
|
||||||
|
|
||||||
|
One caveat: you might have noticed that when you buy an 8GB flash drive, it's not actually 8GB. This is because there are two definitions of a gigabyte (and a megabyte, and a kilobyte…) - 1000 megabytes, and 1024 megabytes (because computers, which use binary, are good with powers of two). Storage manufacturers use the latter, Windows uses the former. Linux and macOS typically use the former definition, too. To distinguish the two, "kibibyte" (abbreviated as KiB rather than KB) means 1024 bytes. There's unfortunately no term that exclusively refers to the 1000 byte definition. Neither definition of a kilobyte is wrong. All of this also applies to kilobytes, terabytes, and so on.
|
||||||
|
|
||||||
|
### GPU
|
||||||
|
|
||||||
|
This is the graphics processing unit. Most modern CPUs have one of these built in, commonly known as an iGPU, the i standing for integrated (as opposed to a dGPU, which is a separate dedicated card). This is most relevant to gaming, and is also used for machine learning, cryptocurrency mining, video editing, etc. If your GPU is especially weak, it may have trouble decoding high resolution video, but with modern computers, this isn't usually something you'll have to worry about.
|
||||||
|
|
||||||
|
### WiFi
|
||||||
|
|
||||||
|
802.11 is the technical name for WiFI. There are various versions of WiFi, with confusing names such as 802.11ac and 802.11n, but you probably won't need to check and compare them. Most devices support more than one standard.
|
||||||
|
|
||||||
|
Technical Terms, Jargon, and Other Gotcha's
|
||||||
|
-------------------------------------------
|
||||||
|
|
||||||
|
### Resolution
|
||||||
|
|
||||||
|
This is how many pixels a screen has. 1080p means a display 1,080 pixels high, typically with 1920x1080 pixels. 4K means 3840x2160, so it can also be called 2160p. You can also find laptops with 1366x768 and 1280x720 screens, but I wouldn't recommend going lower than that last one. 4K is probably overkill, but makes sense on larger screens, or if you're doing graphical design work.
|
||||||
|
|
||||||
|
### Display technologies
|
||||||
|
|
||||||
|
LED and LCD refer to the same technology, with the accurate name being an LCD display with LED backlight. OLED (and AMOLED) use a more sophisticated (and expensive!) technology that has much higher contrast. This is because it doesn't have a backlight like LCD displays do, so when something on the screen is supposed to be pure black, rather than being mostly dark, it's actually pure black, with the total absence of light. An LCD display can't achieve that level of darkness without being turned off entirely.
|
||||||
|
|
||||||
|
I've written more about LCD vs OLED display technologies [here](https://bune.city/2019/05/lynne-teaches-tech-dark-mode/).
|
||||||
|
|
||||||
|
### Optane
|
||||||
|
|
||||||
|
I've seen a few advertisements saying a laptop has "32gb of memory" and then clarifying that they mean "16gb ram, 16gb optane". Optane storage is essentially the same thing as an ssd, but faster. Those laptops have 16gb ram and 16gb of extremely fast storage (in addition to whatever hard drive or ssd it has).
|
||||||
|
|
||||||
|
### USB-C and Thunderbolt
|
||||||
|
|
||||||
|
USB-C refers to a particular type of USB port. It's not compatible with what we all call USB today, which is actually USB-A. (USB-B is mostly used for printers, so much so that many stores sell USB-A to -B connectors as "Printer cables".)
|
||||||
|
|
||||||
|
Thunderbolt is a standard that some USB-C ports support. A non-thunderbolt USB-C port does less than a thunderbolt one, mainly having no support for external displays.
|
||||||
|
|
||||||
|
You can read more about the differences between the various types and standards of USBs [here](https://bune.city/2019/05/lynne-teaches-tech-usb/).
|
||||||
|
|
||||||
|
### big.LITTLE architecture
|
||||||
|
|
||||||
|
This one's exclusive to smartphones.
|
||||||
|
|
||||||
|
A phone that uses this technology has two CPUs inside it, and the phone switches between them depending on battery level, performance, and so on. A phone with two quad-core CPUs using big.LITTLE will often be (technically correctly) marketed as an octo-core phone, even though it's impossible to have all eight of those cores active at once.
|
||||||
|
|
||||||
|
These are the main things to look out for. Thanks for reading!
|
||||||
|
|
||||||
|
|
@ -0,0 +1,70 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: How does HTTPS keep you safe online?"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
HTTPS is an extension to HTTP. It encrypts your traffic to and from a given website, ensuring that nobody can read your activity in transit. It's used almost everywhere, from banking to search engines to this very blog.
|
||||||
|
|
||||||
|
<!--more-->
|
||||||
|
This was the question submitted via the survey:
|
||||||
|
|
||||||
|
> What does TLS protect me from, and what does TLS *not* protect me from?
|
||||||
|
>
|
||||||
|
> <cite>Anonymous survey respondent</cite>
|
||||||
|
|
||||||
|
TLS, or Transport Layer Security, is a cryptographic protocol that replaces its predecessor SSL (Secure Sockets Layer). It is used not only for HTTPS, but also for email, VoIP calls, instant messaging, and more. I'll talk specifically about HTTPS in this article, but most of what I'll be talking about applies to these other applications too.
|
||||||
|
|
||||||
|
How does HTTPS work?
|
||||||
|
--------------------
|
||||||
|
|
||||||
|
Without getting into the specifics, HTTP data is sent over TCP/IP connections through the internet. Each HTTP request and response is split into small TCP packets, and sent to an address specified by IP. The receiving machine reads the HTTP data inside the packets.
|
||||||
|
|
||||||
|
TLS adds another layer. The HTTP data is encrypted with TLS, and then sent using TCP/IP. The receiving machine reads and decrypts the data inside the packets. The data inside the packets is encrypted using a method only the server and client can understand, so nobody else can read the data while it's being sent.
|
||||||
|
|
||||||
|
### The specifics
|
||||||
|
|
||||||
|
When you connect to a TLS secured resource, a *TLS handshake* must first be performed. It goes like this\[efn\_note\]This is a description of the RSA method. There is also the Diffie-Hellman method, which works a little differently. It's less frequently used than RSA. If you'd like to read about it, you can do so [here](https://www.cloudflare.com/learning/ssl/what-happens-in-a-tls-handshake/).\[/efn\_note\]:
|
||||||
|
|
||||||
|
- The client (your web browser) sends a message with a random number (we'll call it *Rc*, the random client number), a list of supported encryption types, and the highest TLS version supported.
|
||||||
|
- The server (the website you're connecting to) sends a reply with another random number (*Rs*), the encryption method the server wishes to use, and the certificate file that verifies that the server is who it says it is.
|
||||||
|
- After the client verifies the certificate, it extracts the server's public PGP key from the certificate The client then uses the public key to encrypt a third random number (*Rp*, also known as the premaster secret), and sends it to the server. A public PGP key is a piece of data you can use to encrypt a message or file so that only the server can decrypt it. It's like the server sent you a padlock, you used it to lock away your secret message, and you send it back to the server, who holds the only key.
|
||||||
|
- The server uses its *private* PGP key to decrypt *Rp*. Both computers now have *Rc*, *Rs*, and *Rp*. Nothing sent so far has been encrypted, which means an attacker could have obtained *Rc* and *Rs*. However, since *Rp* is encrypted using a key that only the server can decrypt, the attacker would be unable to read it. All three numbers are needed to be able to break the encryption, so the attacker wouldn't be able to do anything.
|
||||||
|
- Both the client and the server use the three random numbers to generate a *session key* which is used to encrypt the rest of the connection.
|
||||||
|
- The client and server both send a final message encrypted with the session key. It all has gone well, the client will be able to decrypt the server's message, and vice versa.
|
||||||
|
|
||||||
|
It took a while, but both the client and the server now have a shared key that they can use to encrypt data. Anything sent by the client can only be read by the client and the server, and the same applies to anything sent by the server.
|
||||||
|
|
||||||
|
What does TLS protect you from?
|
||||||
|
-------------------------------
|
||||||
|
|
||||||
|
TLS protects the data as it travels over the internet. Anything you look at will be encrypted using a method that only you (and the server) can decrypt. This means that someone intercepting your connection can't read anything that you or the server is sending. For example, if an attacker was somehow able to "sit between" you and a HTTP connection to a server, they would be able to intercept the TCP packets and read the HTTP data stored within, and see exactly what you see. They would also be able to send their own responses back pretending to be you. With a HTTPS connection, however, they would still be able to intercept the packets, but they wouldn't be able to read what's inside them, or pretend to be you.
|
||||||
|
|
||||||
|
In networking security, people often refer to the CIA\[efn\_note\]This has nothing to do with the USA's Central Intelligence Agency\[/efn\_note\] model of information security: **C**onfidentiality, **I**ntegrity, and **A**vailability. This is a good "rule of thumb" method for determining how safe something is to use. HTTPS communication is Confidential because only you and the server can read the data. There is data Integrity because data can't be modified without both the client and server being able to tell (as any modified data wouldn't be encrypted with the session key). However, it does not provide Availability - an attacker is able to cut off communication between you and the server. Of course, no communication over the internet can provide availability, because nothing can be done about the connection being lost due to someone pulling out the router's power cable.
|
||||||
|
|
||||||
|
What *doesn't* TLS protect you from?
|
||||||
|
------------------------------------
|
||||||
|
|
||||||
|
TLS only protects communications between two computers. If someone is able to hack in to the server, they can read all the messages that are being sent to and from it. This is the same for the client - if your computer is hacked into, an attacker would be able to view your HTTPS traffic.
|
||||||
|
|
||||||
|
Let's say you want to go to [example.com](https://example.com), but you accidentally type [example.net](https://example.net). Even if the TLS encryption works, you're still on the wrong website. example.net might be a malicious website owned by an attacker trying to trick you into providing your example.com login details. Your traffic can still only be read by you and the server, but if the server is malicious, there's nothing you can do.
|
||||||
|
|
||||||
|
There are many different encryption algorithms that a TLS connection can be encrypted with. Every now and then, one of the encryption methods will be found to be insecure. If you're using a (very) outdated web browser, you might not support any encryption methods that haven't been cracked, making TLS much less secure. Wikipedia has [a table](https://en.wikipedia.org/wiki/Transport_Layer_Security#Cipher) listing SSL and TLS encryption algorithms, along with which ones are secure and which aren't.
|
||||||
|
|
||||||
|
TLS doesn't protect you or the server from making bad security decisions. Weak passwords, password reuse, and other poor security practices on your part will not be protected by TLS encryption. Additionally, if the server does not properly encrypt passwords, gets hacked into, or uses bad security questions (for example, the security question "what is your birthday" is terribly insecure if you've ever shared your birthdate with anyone), TLS won't help them there. All TLS does is encrypt data in transit. What happens with that data, or what that data is, is outside of TLS' scope.
|
||||||
|
|
||||||
|
Connecting to a website over HTTPS doesn't hide what URL you're visiting. For example, if you're on [google.com.au](https://google.com.au), and you search for "bunnies", you'll get a URL that looks something like <https://google.com.au/search?q=bunnies>. If an attacker is able to view what URLs you're opening, they'll be able to know what you searched for. Some particularly bad websites send passwords this way (for example, https://example.com/login?username=lynne&password=UhOhSpaghettio), which makes retrieving your login details trivially easy.
|
||||||
|
|
||||||
|
The [PRISM surveillance program](https://en.wikipedia.org/wiki/PRISM_(surveillance_program)) operated by the USA's NSA describes a "Google Frontend Server" which is used to remove SSL encryption, read the previously encrypted data, and re-add the encryption.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
It's entirely possible (and almost certain) that the NSA is still doing this. The PRISM system is used by multiple countries and online services.
|
||||||
|
|
||||||
|
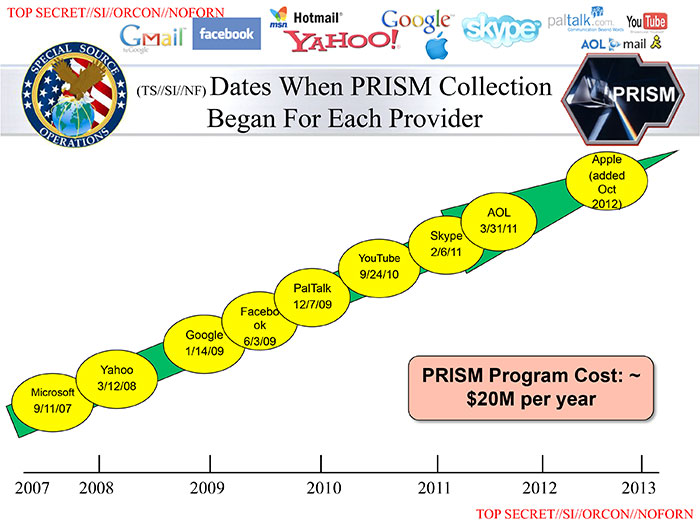
|
||||||
|
|
||||||
|
Summary
|
||||||
|
-------
|
||||||
|
|
||||||
|
TLS protects data in transit. It doesn't protect you or the server from making bad decisions with the data, but it means that nobody can read the data while it's in transit, unless the algorithm you're using is compromised.
|
||||||
|
|
||||||
|
|
@ -0,0 +1,45 @@
|
||||||
|
---
|
||||||
|
title: "Lynne Teaches Tech: Package Managers, the Precursor to the App Store"
|
||||||
|
author: Lynne
|
||||||
|
categories: [Lynne Teaches Tech]
|
||||||
|
tags: [Lynne Teaches Tech]
|
||||||
|
---
|
||||||
|
|
||||||
|
If you use Windows, you're probably familiar with the scenario of installing a program and trying to run it, only to find out that it requires something called ".NET 4.0" to be installed. This is because .NET provides functions that the program makes use of, and thus it requires .NET to work.
|
||||||
|
|
||||||
|
This is called a *dependency*. Some programs have dependencies that are required for them to function properly, and installing the dependency before running the program is necessary.
|
||||||
|
|
||||||
|
mstdn-ebooks is a small program I've made to allow you to host a Fediverse bot that generates posts with words learned from your post history (more about that [here](https://bune.city/2019/05/lynne-teaches-tech-how-do-mstdn-ebooks-bots-work/)). It's written in Python, meaning that it requires Python installed to work. It also uses Mastodon.py and BeautifulSoup, meaning that these need to be installed too. Installing all of this by yourself is a mess. Fortunately, a Python utility called pip can download and install them for you. Pip is a *package manager*.
|
||||||
|
|
||||||
|
When you ask pip to install mstdn-ebooks, it will install Mastodon.py too. It will also install everything Mastodon.py needs, and everything those dependencies need, and so on. This saves you a lot of time and effort!
|
||||||
|
|
||||||
|
Almost all Linux distributions have their own package manager. When you want to install a program, such as Firefox, the package manager will make sure all of the necessary dependencies are installed. The package manager can also update your installed programs and dependencies, meaning that you have one place where you can keep everything up to date. This is in contrast to (most) Windows and macOS programs, which will individually prompt you for an update when you open them.
|
||||||
|
|
||||||
|
{.wp-image-504 width="628" height="149"}
|
||||||
|
|
||||||
|
You might notice that this package manager approach sounds similar to how Android and iOS work. Like with a package manager, programs are installed from one place (Google Play or the App Store) and updated from that same place. When you open VLC on your MacBook, you might get prompted for an update, but this will never happen on your iPhone - the updates come through the App Store.
|
||||||
|
|
||||||
|
There are, however, a few key differences between package managers and mobile app stores.
|
||||||
|
|
||||||
|
Where App Stores Go Wrong
|
||||||
|
-------------------------
|
||||||
|
|
||||||
|
Firstly, mobile app stores don't manage dependencies. If a mobile app needs to use a dependency, it will be included with the app. This means that if you install ten apps that use the same dependency, each app includes a copy of that dependency. This has its advantages and disadvantages, which you can read about in more technical terms [here](https://stackoverflow.com/a/1993407) (the app store method is static and the package manager method is dynamic).
|
||||||
|
|
||||||
|
Secondly, mobile app stores are limited to getting apps from one place. This means that if Google doesn't approve an app, it can never appear in Google Play (ditto for Apple and the App Store). Meanwhile, if (for example) Debian doesn't approve an app for inclusion into their program repository, you can add someone else's repository and install it as normal. This would be like if Google Play had a feature to install and update apps that didn't come from Google. Google and Apple don't provide this because they want to be able to test, mediate, and restrict the apps that can be installed by the end user.
|
||||||
|
|
||||||
|
For example, both Apple and Google have rules against providing donation links in your software. Donations can only be given through in app purchases, meaning that Apple/Google takes a cut. Adding a link to your Patreon or Paypal will get your app removed.
|
||||||
|
|
||||||
|
While it's still possible to install apps outside of Google Play on an Android device, it is discouraged and generally more inconvenient. Meanwhile, on an Apple device, this is not possible for the typical end user at all without jailbreaking the device. This means that getting your app distributed to most Android and iOS users requires you to go through the app store, giving Google and Apple an unavoidable monopoly over the distribution of software. Both Google and Apple charge a fee to list your app on their stores, and they also take a cut of any in-app purchases the end user makes. Meanwhile, if a Linux distribution were to do something like this (and none ever have), people would simply make a new store for users to use, and switching to it would be as easy as adding one line to a configuration file.
|
||||||
|
|
||||||
|
Banning donation links and requiring publishing fees make it difficult for developers of [free and open source](https://bune.city/2019/05/lynne-teaches-tech-what-is-free-software/) software to put their apps on the stores, and thus difficult to distribute their apps at all. Meanwhile, many Linux distributions encourage developers to make their software free and open source, and a few even require it.
|
||||||
|
|
||||||
|
There are a few alternative app stores available for Android devices. One of them is F-Droid, an app that behaves much more like a traditional package manager than a mobile app store. Updates and installations are still handled through F-Droid, but unlike Google Play, all apps are required to be free and open source, donations are permitted, there are no app fees, and it's possible to add alternative vendors to the app (meaning that even if F-Droid doesn't approve the app, you can add a distributor who does and still install the app through the F-Droid app). F-Droid takes this philosophy a step further and warns users of "anti-features" that some apps have. For example, all apps that track users in some way have a warning stating so. You can read more about anti-features [here](https://f-droid.org/wiki/page/Antifeatures).
|
||||||
|
|
||||||
|
Conclusion
|
||||||
|
----------
|
||||||
|
|
||||||
|
Package managers and app stores provide a repository for users to download and update software without having to worry about using installers full of ads, websites presenting fake downloads, and websites getting hacked to distribute virus-laden installers. At the same time, the centralisation of distribution provides an avenue for those distributing the software to exert control over the available packages, which can be a good thing (preventing viruses from being available for download) and a bad thing (Google and Apple banning donation links).
|
||||||
|
|
||||||
|
Thanks for reading! :mlem:
|
||||||
|
|
||||||
Loading…
editor.table_modal.header
Reference in a new issue